
 |
福州大学厦门工艺美术学院的研究团队在《Scientific Reports》发表了一项创新研究。他们首次系统比较了SHAP、LIME等四种可解释AI算法在教育数据挖掘中的表现,通过倾向得分匹配(PSM)验证了关键特征的因果效应。研究收集了来自两所高校1086名艺术类新生的78维问卷数据,涵盖个人特质、家庭背景等212个特征,采用中国教育追踪调查(CEPS)框架的认知能力评估体系作为标准。
研究主要运用了五项关键技术:1)基于树结构Parzen估计(TPE)的超参数优化算法自动调参;2)随机森林(RF)与XGBoost等五种机器学习模型对比;3)SHAP值分析和LIME局部解释方法;4)Morris全局敏感性分析;5)倾向得分匹配(PSM)因果验证。通过7:2:1的数据划分和交叉验证,确保模型可靠性。
【特征识别】
通过RF建模显示,自我评估的数学能力(w2b02)和学业期望(w2b18)的特征重要性最高(0.3233/0.2545)。Morris敏感性分析证实w2b18的μ*=0.4108具有最显著的平均效应。
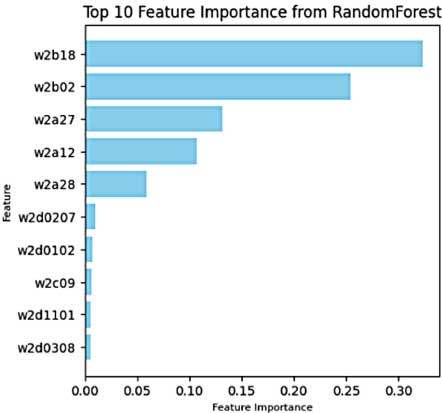
【算法差异】
SHAP和特征重要性更关注家庭因素(占比35%),而LIME独特识别出健康相关特征。Morris敏感性展现出最均衡的特征分布,其交互效应指标θ*揭示了w2a27等变量的稳定性差异。
【因果验证】
PSM分析显示父母期望(w2a27)的ATT=0.181(p<0.001),Rosenbaum检验证实即使存在未观测混杂(Gamma=2)时结论仍稳健。数学自我效能感(w2b02)呈现负向效应(ATT=-0.214),暗示数学焦虑可能抑制艺术生的认知发展。
这项研究开创性地构建了教育数据挖掘的可解释性分析框架。其发现不仅证实了班杜拉自我效能理论在跨学科场景的适用性,更通过Morris敏感性指标揭示了家庭期望与学业表现的复杂交互机制。技术层面提出的损失函数改进方案(公式8),为协调不同解释算法的输出差异提供了可行路径。对教育实践的启示在于:艺术类院校应考虑开设数学-艺术融合课程,同时建立家校联动的认知发展监测体系。未来研究可结合多模态数据,进一步探索生理指标与认知能力的深层关联。
转载请注明:可思数据 » 解码学生认知能力:教育数据挖掘中可解释AI算法的比较研究及其应用价值
免责声明:本站来源的信息均由网友自主投稿和发布、编辑整理上传,或转载于第三方平台,对此类作品本站仅提供交流平台,不为其版权负责。本网站对有关资料所引致的错误、不确或遗漏,概不负任何法律责任。若有来源标注错误或侵犯了您的合法权益,请作者持权属证明与本站联系,我们将及时更正、删除,谢谢。联系邮箱:elon368@sina.com


