火爆的图机器学习,2020年将有哪些研究趋势?
本文转自雷锋网,如需转载请至雷锋网官网申请授权。
2019年绝对是图机器学习(GML)大火的一年,凡是学术会议,图神经网络的会场总会爆满。
图机器学习的研究之所以在2019年突然变得火热,原因在于,在前几年尽管深度学习在欧氏空间中的数据方面取得了巨大的成功,但在许多实际的应用场景中的数据往往是从非欧式空间生成的。
正如阿里达摩院曾在2019年所提:“单纯的深度学习已经成熟,而结合了深度学习的图研究将端到端学习与归纳推理相结合,有望解决深度学习无法处理的关系推理、可解释性等一系列问题。”
在过去的一年里,图机器学习经过了蓬勃的发展,这从各大顶会中图机器学习的火爆场面也可以看出。
而新的一年已经过去了一个月,那么2020年图机器学习的火热还能持续吗?又将有哪些新的研究趋势呢? 即将于4月份在埃塞俄比亚举办的ICLR 2020是一个能够很好反映这些问题的会议。
这个会议是由深度学习三巨头之二的 Yoshua Bengio 和 Yann LeCun 牵头创办,旨在关注有关深度学习各个方面的前沿研究。
在ICLR 2020中共有150篇投稿与图机器学习有关,而其中有近1/3的论文都被录用了,这也说明图机器学习火热依旧。
我们不妨将这些论文按照理论、应用、知识图谱、图嵌入来划分,从而一窥图机器学习在2020年的研究趋势。
注:文中涉及论文,可关注雷锋网「AI科技评论」微信公众号,并后台回复「2020年GML趋势」下载。
1、GNN理论知识会更加扎实
从目前的形式看,图机器学习的领域在成熟的康庄大道上越走越远,但是图神经网络还有很多进步空间。过去的一年图神经网络不断改进,因此诞生了许多理论研究,在我们对2020年预测之前,先来简单梳理一下图神经网络的重要理论成果吧!
What graph neural networks cannot learn: depth vs width
https://openreview.net/forum?id=B1l2bp4YwS
洛桑联邦理工学院 Andreas Loukas 的这篇论文,无论在影响力、简洁性还是对理论理解的深度上,无疑是论文中的典范。
它表明,当我们用GNN计算通常的图问题时,节点嵌入的维数(网络的宽度,w)乘以层数(网络的深度,d)应该与图n的大小成正比,即dW=O(n)。
但现实是当前的GNN的许多实现都无法达到此条件,因为层数和嵌入的尺寸与图的大小相比还不够大。另一方面,较大的网络在实际操作中不合适的,这会引发有关如何设计有效的GNN的问题,当然这个问题也是研究人员未来工作的重点。需要说明的是,这篇论文还从80年代的分布式计算模型中汲取了灵感,证明了GNN本质上是在做同样的事情。
这篇文章还包含有大量有价值的结论,强烈建议去阅读原文。可关注雷锋网(公众号:雷锋网)「AI科技评论」微信公众号,后台回复「2020年GML趋势」下载论文。
同样,在另外两篇论文中,Oono等人研究了GNN的能力。第一篇文章是《图神经网络在节点分类中失去了表达能力》,第二篇文章是《图神经网络的逻辑表达》。
Graph Neural Networks Exponentially Lose Expressive Power for Node Classification
https://openreview.net/forum?id=S1ldO2EFPr
这篇论文表明:“在已知某些条件下的权重,当层数增加时,GCN除了节点度和连通分量以外,将无法学习其他任何内容。”这一结果扩展了“马尔可夫过程收敛到唯一平衡点”的性质,并表明其中收敛速度由转移矩阵的特征值决定。
The Logical Expressiveness of Graph Neural Networks
https://openreview.net/pdf?id=r1lZ7AEKvB
这篇论文展示了GNN与节点分类器类型之间的联系。在这之前,我们已经了解GNN与WL同构检验一样强大。但是GNN可以获得其他分类功能么?直观上不行,因为GNN是一种消息传递机制,如果图的一个部分和另一个部分之间没有链接,那么两者之间就不会传递消息。
因此论文提出一个简单解决方案:在邻域聚合之后添加一个读出操作,以便每个节点在更新所有要素时与图中所有其他节点都有联系。
其他在理论上的工作还有很多,包括Hou等人测量GNN的图形信息的使用。以及 Srinivasan 和 Ribeiro提出的基于角色的节点嵌入和基于距离的节点嵌入的等价性讨论。
论文链接如下:
Measuring and Improving the Use of Graph Information in Graph Neural Networks
https://openreview.net/forum?id=rkeIIkHKvS
On the Equivalence between Positional Node Embeddings and Structural Graph Representationshttps://openreview.net/forum?id=SJxzFySKwH
2、新酷应用不断涌现
在过去的一年中,GNN已经在一些实际任务中进行了应用。例如已经有一些程序应用于玩游戏、回答智商测试、优化TensorFlow计算图形、分子生成以及对话系统中的问题生成。
HOPPITY: LEARNING GRAPH TRANSFORMATIONS TO DETECT AND FIX BUGS IN PROGRAMS
https://openreview.net/pdf?id=SJeqs6EFvB
在论文中,作者其提出了一种在Javascript代码中同时检测和修复错误的方法。具体操作是将代码转换为抽象语法树,然后让GNN进行预处理以便获得代码嵌入,再通过多轮图形编辑运算符(添加或删除节点,替换节点值或类型)对其进行修改。为了理解图形的哪些节点应该修改,论文作者使用了一个指针网络(Pointer network),该网络采用了图形嵌入来选择节点,以便使用LSTM网络进行修复。当然,LSTM网络也接受图形嵌入和上下文编辑。
LambdaNet: Probabilistic Type Inference using Graph Neural Networks
https://openreview.net/pdf?id=Hkx6hANtwH
类似的应用还体现在上面这篇论文中。来自得克萨斯大学奥斯汀分校的作者研究了如何推断像Python或TypeScript此类语言的变量类型。更为具体的,作者给出了一个类型依赖超图(type dependency hypergraph),包含了程序作为节点的变量以及它们之间的关系,如逻辑关系、上下文约束等;然后训练一个GNN模型来为图和可能的类型变量产生嵌入,并结合似然率进行预测。
Abstract Diagrammatic Reasoning with Multiplex Graph Networks
https://openreview.net/pdf?id=ByxQB1BKwH
在智商测试类的应用中,上面这篇论文展示了GNN如何进行IQ类测试,例如瑞文测验(RPM)和图三段论(DS)。具体的在RPM任务中,矩阵的每一行组成一个图形,通过前馈模型为其获取边缘嵌入,然后进行图形汇总。由于最后一行有8个可能的答案,因此将创建8个不同的图,并将每个图与前两行连接起来,以通过ResNet模型预测IQ得分。如下图所示:
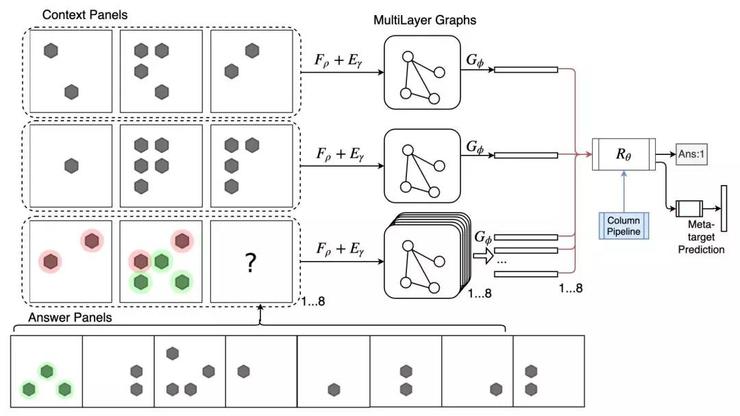
来自:https://openreview.net/pdf?id=ByxQB1BKwH
Reinforced Genetic Algorithm Learning for Optimizing Computation Graphs
https://openreview.net/pdf?id=rkxDoJBYPBDeepMind
在上面的论文中提出了一种RL算法来优化TensorFlow计算图的开销。先通过标准GNN对图形进行处理,然后产生与图中每个节点的调度优先级相对应的离散化嵌入,最后将嵌入被馈送到遗传算法BRKGA中进行模型训练,从而优化得到的TensorFlow图的实际计算开销。值得注意的是该遗传算法决定每个节点的布局和调度。
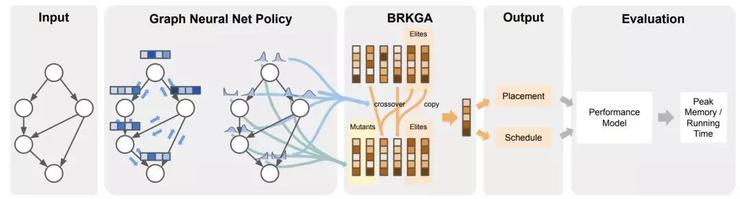
类似的炫酷应用还有Chence Shi的分子结构生成和Jiechuan Jiang玩游戏以及Yu Chen的玩游戏等等。
论文链接如下:Graph Convolutional Reinforcement Learning
https://openreview.net/forum?id=HkxdQkSYDB
Reinforcement Learning Based Graph-to-Sequence Model for Natural Question Generation
https://openreview.net/forum?id=HygnDhEtvr
3、知识图谱将更加流行
在今年的ICLR会议上,有很多关于知识图谱推理的论文。
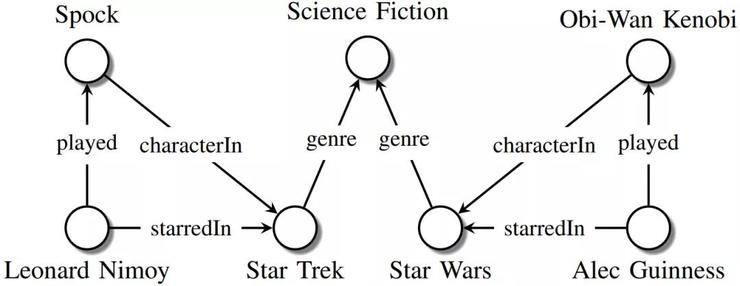
知识图谱例子(来源:https://arxiv.org/abs/1503.00759)
从本质上讲,知识图谱是一种结构化的表示事实的方式。与一般的图不同,知识图谱的节点和边实际上具有一定的含义,例如演员的名字、电影名等。知识图谱中一个常见的问题是,如何回答一些复杂问题,例如“斯皮尔伯格哪些电影在2000年之前赢得了奥斯卡奖?”,这个问题翻译成逻辑查询语言则是:
∨ {Win(Oscar, V) ∧ Directed(Spielberg, V) ∧ProducedBefore(2000, V) } Query2box:
Reasoning over Knowledge Graphs in Vector Space Using Box Embeddings
https://openreview.net/forum?id=BJgr4kSFDS
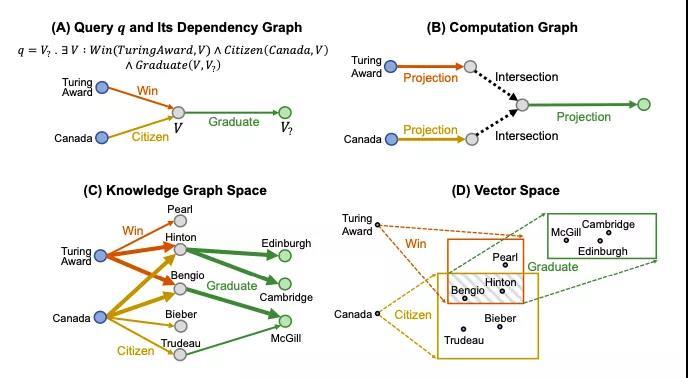
Query2Box 推理框架 在斯坦福大学Hongyu Ren等人的工作中,他们建议将query嵌入到隐空间当中,而不是作为单个的点(作为矩形框)。
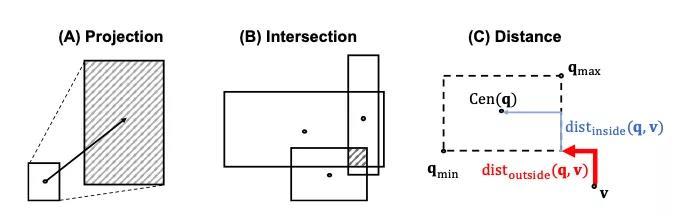
QUERY2BOX的两种操作及距离函数的几何示例 这种方法使得可以自然地执行 交 操作(即合取 ∧),得到一个新的矩形框。但是对于 并 操作(即析取 ∨)却并不那么简单,因为它可能会产生非重叠区域。
此外,要使用嵌入来对所有query进行精确建模,嵌入之间的距离函数(通过VC维度进行度量)的复杂性会与图谱中实体的数量成正比。
不过有一个不错的技巧可以将析取( ∨)query转换为DNF形式,这时候只有在图计算的最后才会进行 并 操作,这能够有效减少每个子查询的距离计算。
Differentiable Learning of Numerical Rules in Knowledge Graphs
https://openreview.net/forum?id=rJleKgrKwSCMU的Po-Wei
Wang等人在类似主题的一篇文章提出了一种处理数字实体和规则的方法。
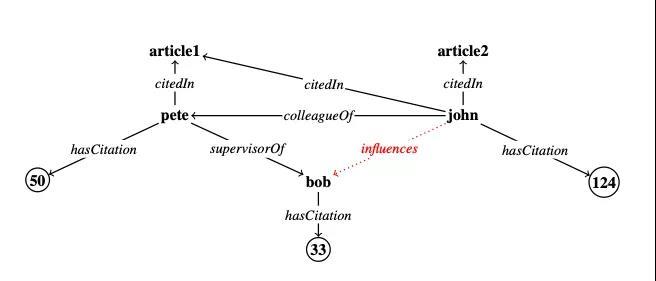
引用知识图谱(Citation KG)示例 举例来说,以引用知识图谱(Citation KG),可以有一条规则: influences(Y,X) ← colleagueOf(Z,Y) ∧ supervisorOf(Z,X)∧ hasCitation>(Y,Z) 这是一个典型的情况,即学生X受到其导师Z的同事Y(Y有较高的引用率)的影响。
这个规则右边的每个关系都可以表示为一个矩阵,而寻找缺失连接(missing links)的过程可以表示为关系与实体向量的连续矩阵乘积,这个过程称为规则学习。由于矩阵的构造方式,神经网络的方法只能在分类规则colleagueOf(Z,Y)下工作。
作者的贡献在于,他们通过一种新颖的方法证明了,在实际中并不需要显式地表示这些矩阵,从而有效地处理了类似hasCitation>(Y,Z)、求反运算这样的数字规则,这大大降低了运行时间。
You CAN Teach an Old Dog New Tricks!
On Training Knowledge Graph Embeddingshttps://openreview.net/forum?id=BkxSmlBFvr
在今年的图神经网络(或者说机器学习)中经常出现的一个研究方向是:对现有模型的重新评估,以及在一个公平环境中进行测评。
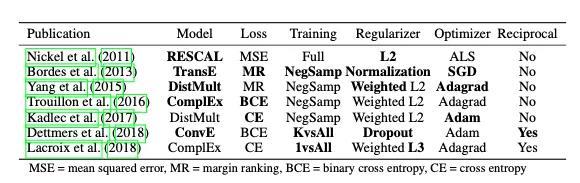
上面这篇文章即是其中一个,他们的研究表明,新模型的性能往往取决于试验训练中的“次要”细节,例如损失函数的形式、正则器、采样的方案等。
在他们进行的大型消融研究中,作者观察到将旧的方法(例如RESCAL模型)的超参数进行适当调整就可以获得SOTA性能。 当然在这个领域还有许多其他有趣的工作,Allen et al. 基于对词嵌入的最新研究,进一步探究了关系与实体的学习表示的隐空间。Asai et al. 则展示了模型如何在回答给定query的Wikipedia图谱上检索推理路径。
Tabacof 和 Costabello 讨论了图嵌入模型的概率标定中的一个重要问题,他们指出,目前流行的嵌入模型TransE 和ComplEx(通过将logit函数转换成sigmoid函数来获得概率)均存在误校,即对事实的存在预测不足或预测过度。
论文链接如下:On Understanding Knowledge Graph Representation
https://openreview.net/forum?id=SygcSlHFvS
Learning to Retrieve Reasoning Paths over Wikipedia Graph for Question Answering
https://openreview.net/forum?id=SJgVHkrYDH
Probability Calibration for Knowledge Graph Embedding Models
https://openreview.net/forum?id=S1g8K1BFwS
4、图嵌入的新框架
图嵌入是图机器学习的一个长期的研究主题,今年有一些关于我们应该如何学习图表示的新观点出现。
GraphZoom: A Multi-level Spectral Approach for Accurate and Scalable Graph Embedding
https://openreview.net/forum?id=r1lGO0EKDH
康奈尔的Chenhui Deng等人提出了一种改善运行时间和准确率的方法,可以应用到任何无监督嵌入方法的节点分类问题。 这篇文章的总体思路是,首先将原始图简化为更小的图,这样可以快速计算节点嵌入,然后再回复原始图的嵌入。
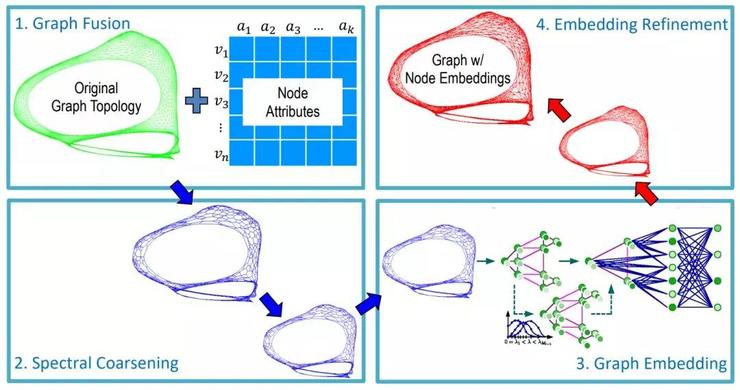
最初,根据属性相似度,对原始图进行额外的边扩充,这些便对应于节点的k近邻之间的链接。 随后对图进行粗化:通过局部谱方法将每个节点投影到低维空间中,并聚合成簇。任何无监督的图嵌入方法(例如DeepWalk、Deep Graph Infomax)都可以在小图上获得节点嵌入。 在最后一步,得到的节点嵌入(本质上表示簇的嵌入)用平滑操作符迭代地进行广播,从而防止不同节点具有相同的嵌入。 在实验中,GraphZoom框架相比node2vec和DeepWalk,实现了惊人的 40 倍的加速,准确率也提高了 10%。
A Fair Comparison of Graph Neural Networks for Graph Classification
https://openreview.net/forum?id=HygDF6NFPB
已有多篇论文对图分类问题的研究成果进行了详细的分析。比萨大学的Federico Errica 等人在图分类问题上,对GNN模型进行了重新评估。
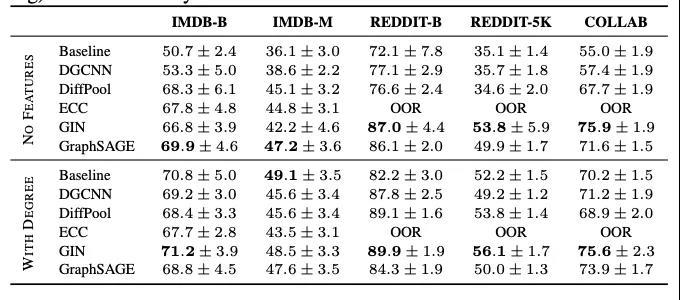
他们的研究表明,一个不利用图的拓扑结构(仅适用聚合节点特征)的简单基线能获得与SOTA GNN差不多的性能。事实上,这个让人惊讶的发现,Orlova等人在2015年就已经发表了,但没有引起大家的广泛关注。
Understanding Isomorphism Bias in Graph Data Sets
https://openreview.net/forum?id=rJlUhhVYvSSkolkovo
科学技术研究院的Ivanov Sergey等人在研究中发现,在MUTAG和IMDB等常用数据集中,即使考虑节点属性,很多图也都会具有同构副本。而且,在这些同构图中,很多都有不同的target标签,这自然会给分类器引入标签噪声。这表明,利用网络中所有可用的元信息(如节点或边属性)来提高模型性能是非常重要的。
Are Powerful Graph Neural Nets Necessary? A Dissection on Graph Classification
https://openreview.net/forum?id=BJxQxeBYwH
另外还有一项工作是UCLA孙怡舟团队的工作。这项工作显示如果用一个线性近邻聚合函数取代原有的非线性近邻聚合函数,模型的性能并不会下降。这与之前大家普遍认为“图数据集对分类的影响并不大”的观点是相反的。同时这项工作也引发一个问题,即如何为此类任务找到一个合适的验证框架。

时间:2020-02-06 22:35 来源:可思数据 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
- [机器学习]2021年进入AI和ML领域之前需要了解的10件事
- [机器学习]来自Facebook AI的多任务多模态的统一Transformer:向
- [机器学习]一文详解深度学习最常用的 10 个激活函数
- [机器学习]更深、更轻量级的Transformer!Facebook提出:DeLigh
- [机器学习]AAAI21最佳论文Informer:效果远超Transformer的长序列
- [机器学习]深度学习中的3个秘密:集成、知识蒸馏和蒸馏
- [机器学习]让研究人员绞尽脑汁的Transformer位置编码
- [机器学习]【模型压缩】深度卷积网络的剪枝和加速
- [机器学习]堪比当年的LSTM,Transformer引燃机器学习圈:它是
- [机器学习]Transformer又又来了,生成配有音乐的丝滑3D舞蹈,
相关推荐:
网友评论:















