如何找到好的主题模型量化评价指标?这是一份热门方法总结
基于统计学的主题模型诸如 LDA(Latent Dirichlet Allocation),Biterm 的应用使得针对大量文本进行信息的总结提取成为可能。但是提取的主题到底质量如何,如何进行量化分析和评价,仍然没有确定的标准。
同时,随着神经网络的发展,encoding-decoding, GAN 这种非监督模型开始进入到主题模型的应用中来,如何判断这些模型产生的主题有效性就更显得重要了。同时,这些神经网络本身也可以作为评测的方法之一。
本文就主题模型的评价指标进行讨论,对当下比较热门的评价方法进行总结,并对未来这一领域可能的发展方向进行展望。
1. 主题模型
宏观上讲,主题模型就是用来在一系列文档中发现抽象主题的一种统计模型,一般来说,这些主题是由一组词表示了。如果一篇文章有一个中心思想,那么一些特定词语会更频繁的出现。比方说,如果一篇文章是在讲狗的,那「狗」和「骨头」等词出现的频率会高些。如果一篇文章是在讲猫的,那「猫」和「鱼」等词出现的频率会高些。而有些词例如「这个」、「和」大概在两篇文章中出现的频率会大致相等。如果一篇文章 10% 和猫有关,90% 和狗有关,那么和狗相关的关键字出现的次数大概会是和猫相关的关键字出现次数的 9 倍。而一个主题模型则会用数学框架来体现文档的这种特点。
如图 1 所示,最左边的就是各个主题(提前确定好的),然后在文中不同的颜色对应不同的主题,比如黄色可能对应狗,那么文中跟狗相关的词都会标成黄色,这样最后就能获得一个各个主题可能的主题分布。
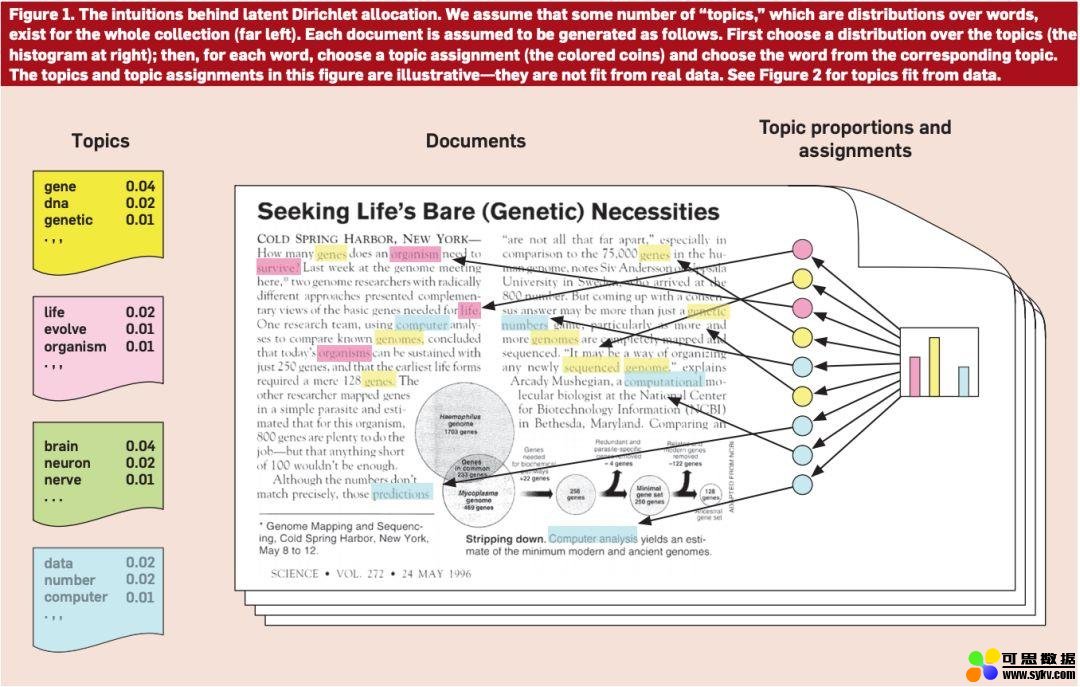
图 1:主题模型(图源:https://medium.com/@tengyuanchang/%E7%9B%B4%E8%A7%80%E7%90%86%E8%A7%A3-lda-latent-dirichlet-allocation-%E8%88%87%E6%96%87%E4%BB%B6%E4%B8%BB%E9%A1%8C%E6%A8%A1%E5%9E%8B-ab4f26c27184)
本文主要是介绍主题模型的量化评价指标,因此不对主题模型做过多解释。如果对主题模型没有什么基础的,可以看一下机器之心发过的一篇比较适合入门的教程,有需要可以自取。同时,除了教程中提到的这些概率模型,一些深度学习模型(GAN, Encoding-Decoding 等)也开始进入这一领域,比如基于 GAN 的 ATM(Adversarial-neural Topic Model)就有不错的表现。
观察上文提到的那些主题模型,可以发现不管是概率模型 LDA,还是基于深度学习模型 ATM,都面临一个问题,那就是这些模型该怎么去评价,这些模型提取出的主题真的有用吗?换句话说,这些模型提取出的东西真的能表达一个主题吗?举个很简单的例子,当主题模型提取出一个主题(很多词)时,如果这么模型是好的,那么这些词一定是能表达同一个主题的,如果不好的话那这些词就是貌合神离。一般来说,主题越多,我们得到的结果就越有分辨性,但是对应的,当主题变多时,结果毫无意义的情况就更加普遍,有些主题只有几个词,而且根本词不对题。除此之外,经过一些专家的实验,发现貌合神离的情况主要有以下四种:
a. 通过词对联系传递后才联系在一起的主题。比如说,「糖」,「甘蔗」和「糖醋排骨」,糖产生自甘蔗(主题可以是「甜食」),糖醋排骨中加了糖(主题可以是「料理」),糖醋排骨跟甘蔗却很难组成一个主题。但是在关系传递中(通过「糖」联系在一起),这三个词被放到了同一个主题中。
b. 异常词。由于算法错误或其他什么原因导致完全不相干的词出现在这个主题中。
c. 关系不明。词之间没有很明确的联系。
d. 不平衡。词之间的联系都很明确,但是词的意义都很宽泛,比如「学科」和「作业」,很难确定一个很明确的主题。
本文剩下的部分首先对两类评价模型进行介绍,然后分析了这些评价模型的效果,最后对评价模型的发展进行了展望。
2 利用模型中的知识评价主题模型
目前评价的方法大部分都利用了一些参数或者是词之间的联系来确定模型的优劣,很少有直接利用模型中获得的东西来衡量主题模型的。Xing [4] 最近提出了几种基于 Gibbs Sampling 过程中估算出的分布进行评价的方式。
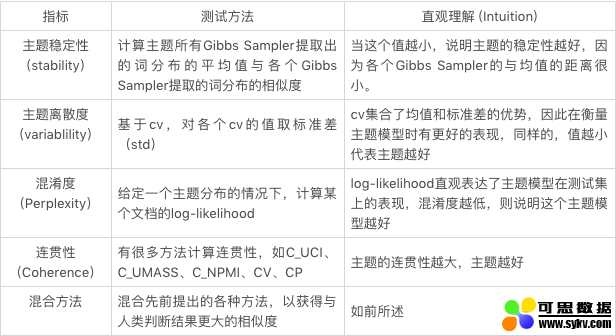
2.1 主题稳定性
在 LDA 的 Gibbs Sampling 的过程中会产生(估算)两个分布——一个是给定文档时主题的分布,另一个是给定主题时词的分布 (Φ),而主题稳定性主要考虑的就是第二个分布。
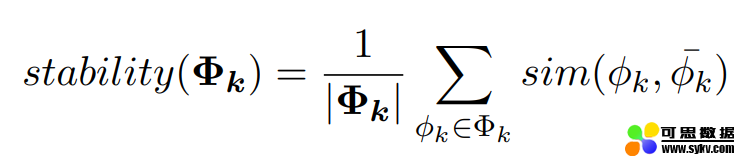
如公式所示,对于一个给定的主题 k,要计算其所有 Gibbs Sampler 提取出的词分布的平均值与各个 Gibbs Sampler 提取的词分布的相似度 (原论文 [4] 中使用了 cosine similarity, Euclidean distance, KL-divergence 以及 Jaccard similarity 来计算这个相似度),取和后就得到了这个主题的主题稳定度。
通过公式可以很清晰的看出,相较于前面的计算方式,主题稳定性并不需要参数和多余的语料库。然而,有些常用词的词频很高,因此出现在主题中时主题的稳定度会很高,但是它们跟主题却并不相关,这也就导致一些很差的主题有很高的主题稳定度。
2.2 主题离散度
在前一节中提到过,Gibbs Sampling 产生了两个分布,主题稳定性使用了第二个分布,也就是通过词的角度来判断主题的优劣。而本节的离散度使用的则是第一个分布,也就是说我们的目光转向了文档这一层次。通常来说,这个的参数是通过对多个 Gibbs Sampler 的结果取平均而得到的。同时,从这些 Gibbs Sampler 的结果中,我们还可以得到他们的标准方差(standard deviation)。但是标准方差太过敏感,于是为了能够获得一个更稳定的结果,我们还可以用平均值除以偏差,以得到变异系数(coefficient of variance,cv)。按常理说,均值和变异系数都可以用来辨别一个主题的好坏,好主题的均值和 cv 应该相对较小,反之则应该较大。在 NYT 语料库的测试中,这三个评判标准的效果如下图所示。
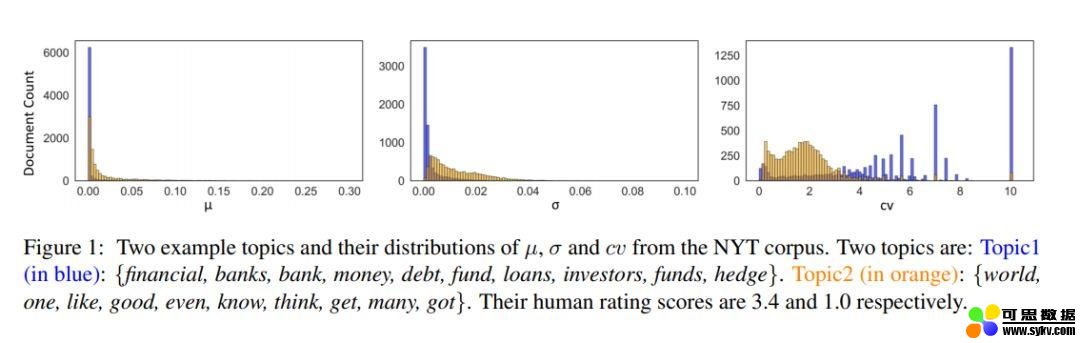
图 2:通过的得到的三种评测结果(图源:https://arxiv.org/abs/1909.03524)
图 2 中,蓝色代表好主题(3.4 分),橘色代表差主题(1 分),可以看到只有 cv 对于两个主题的区分度最大,而平均值(mu)和标准方差(sigma)中,蓝色和橘色的区分度并不大,也就是说很难分辨出好主题和差主题。
因此,cv 是表征主题离散度最好的方式,所以某个主题 k 的主题离散度的计算公式可以表达为:

D 表示第 D 篇文章,k 则表示主题 k。
3. 模拟人工评测结果
在第一节中提到了主题模型常出现的各种误差,基于这些误差,很多人提出了不同的方法,这些方法(包括本文后面提到的)都是为了解决上述一个或多个问题。目前传统的方法大都是使用了目测或是先验知识,常见的方法有很多。最直观的方法就是让人来判断提取出的主题好还是不好,但是很明显,这个方法需要大量的人力物力和时间。因此,人们开始探索如何用公式或是算法来模拟、估计人为判断的结果。人为判断的方法主要分为直接方法和间接方法(后文详述),因此那些模拟人为判断的算法也就大致可以被分为这两类。当然这些方法的分类很多,但在本节中介绍的主要是模拟人工测评结果的那一部分,所以分类就按照直接方法和间接方法来分。
有些方法被称为直接方法,这些方法主要基于语言的内部特性进行判断,比如说 Newman et al. (2010) 提出的主题连贯性(Topic Coherence)就利用 PMI(Pairwise Pointwise Mutual Information)对主题词间的连贯性进行计算,后面其他人也对这种连贯性的计算方式进行了改进,但是本质上还是在计算连贯性(会在后文详述);还有一些方法被称为间接方法,这些方法不是直接通过语言内部特性进行判断的,而是采用一些其它的方式,比如在下游任务中的表现,或是在测试集中的表现(混淆度,perplexity)。就包括。本节剩下的部分就会对这些方法进行详述。
3.1 混淆度 (perplexity)
简单来说,混淆度就是利用概率计算某个主题模型在测试集上的表现,混淆度越低,则说明这个主题模型越好。具体来说,就是在给定一个主题分布的情况下,计算某个文档的 log-likelihood。在下面这个式子里,Phi 代表给定的主题矩阵,α参数确定主题的分布,w 则指代我们要预测的文章(d,与训练得到和α的文章的主题相同)。
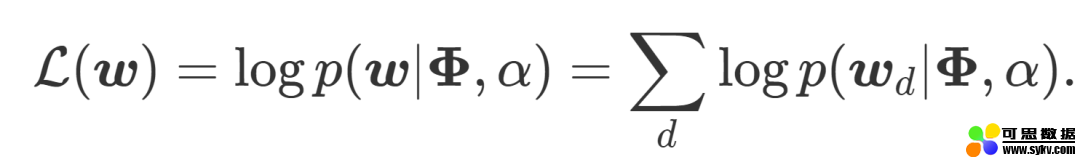
得到了 log-likelihood 后,perplexity 就很好计算了,公式如下(这里的分母一般来说就是文章的单词数):
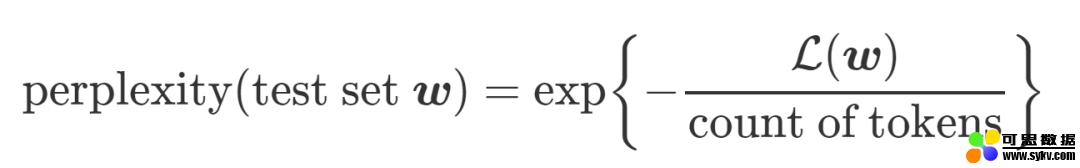
根据定义可以看出,log-likelihood(log-可能性)越高,也就意味着提取出的主题能表达特定主题的能力越好,这个提取出的主题质量也就越高,混淆度也就越小。但是这里的 log-likelihood 是没办法求的,Wallach09a (http://dirichlet.net/pdf/wallach09evaluation.pdf)中提出了一些对 likelihood 进行估计的方法,感兴趣的可以自己看一下,因为其效果并不很好(下面会介绍原因),故而这里对其计算方法就不做详述了。
但是为了测试这个方法的有效性,有人在 Amazon Mechanical Turk 平台上进行了一个大规模实验。他们在每个话题中找到了基于 perplexity 确定的最有可能的 5 组词,然后随机加入了第六组词,让参与者找出这组随机加入的词。
如果每个参与者都能识别出异常词,那么我们可以认为这个提取出的主题是优秀的,可以描述出一个特定的主题。然而,如果许多人把正常的 5 组词中的一组认成异常词,这就意味着他们看不出这些词之间的联系有什么逻辑,我们也就可以认为这个主题不够好——因为它描述的主题并不明确。这个实验证明了混淆度的结果与人为判断的结果不太相关。
3.2 主题连贯性(Coherence)
由于混淆度在很多场景的应用效果不佳,本部分将着重介绍最后一个方法,也就是主题连贯性。主题连贯性主要是用来衡量一个主题内的词是否是连贯的。那么这些词怎么就算是是连贯的呢?如果这些词是相互支撑的,那么这组词就是连贯的。换句话说,如果把好多个主题的词放在一起,用完美的聚类器做聚类,那么同一个主题的词应该在同一个类别中。根据定义可以发现,第一节中提到的四个问题中的前三个,都可以通过主题连贯性解决。
Newman et al. (2010) 提出使用 PMI 计算主题连贯性后,Mimno et al. (2011) 基于主题连贯性的理念,又使用了一种基于条件概率的方式对连贯性进行计算,Musat et al. (2011) 也在同年提出利用 WordNet 的层级概念来获取主题间的联系;然后,Aletras and Stevenson (2013a) 也提出了一种基于分布相似度的方法来求连贯性。目前来说,比较常见的几种方法(Roder et al. (2015) 中整理的,在 Gensim 中有打包好的函数,可以直接调用)如下所示(假设有一个主题,包含 {game, sport, ball, team}):
PMI:为了了解其他几种方式的计算方法,首先要先看一下 PMI 的计算方法(如下图所示)。在后面的两个方法中,这里epsilon 的越小,将会得到越小的结果。这个公式可能看起来有些费解,不过没关系,可以先放一下,在后面看到例子之后,这个公式就很好理解了。
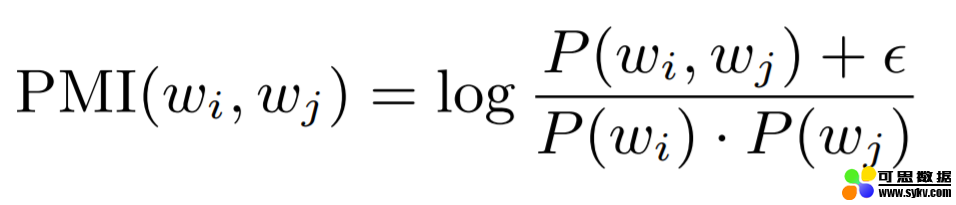
C_uci:本方法由 University of California Irvine(UCI)的 David Newman 提出,故而称其为 UCI 方法。本方法的基本原理是基于滑动窗口,对给定主题词中的所有单词对(one-set 分割)的点态互信息 (point twise mutual information, PMI) 进行计算。





C_v (Coefficient of variance):本方法基于滑动窗口,对主题词进行 one-set 分割(一个 set 内的任意两个词组成词对进行对比),并使用归一化点态互信息 (NPMI) 和余弦相似度来间接获得连贯度。
C_p:本方法也是基于滑动窗口,但分词方法为 one-preceding(每个词只与位于其前面和后面的词组成词对),并利用 Fitelson 相关度来表征连贯度。
3.3 模拟人工判别结果
3.3.1 间接方法
如前文所述,人工判别方法也被分为两类,一类是直接方法,一类是间接方法。人工判别的间接方法被称为异常词检测,主要就是在主题模型提取出的各个主题中加入一个异常词,然后让人来找出这个异常词。
为了模拟这种间接人工判别的结果,Jey Han Lau(2014)从那些发给人工做判别的主题词中提取了词之间的联系特征,提取的方法为以下三种:
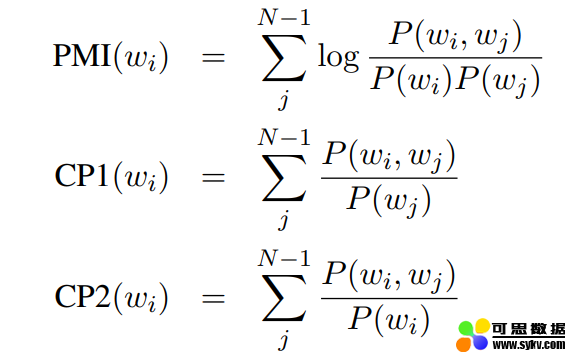
然后将这些特征进行合并,利用 Ranking SVM Regression 来找到异常词。同时,Jey 还利用了 NPMI 进行词之间的联系特征进行提取。最终的结果如下图所示:

相关度比较结果(图源:https://www.aclweb.org/anthology/E14-1056.pdf)
图中显示的是 Jey 的方法(WI-Auto-PMI, WI-Auto-NPMI)与人工判别(WI-Human)的关联度,可以看到这些方法与人工判别得到的结果还是比较一致的。
3.3.2 直接方法
另外一种人工方法叫直接方法,这种方法就比较简单粗暴,就是让人直接对各个主题进行评分。对于这种直接方法,Jey 使用了以下 4 中方法对主题进行评分:
OC(Observed Coherence)-Auto-PMI:对一个主题内的词计算 PMI,计算方法其实就是 PMI,如下图所示:



相关度比较结果(图源:https://www.aclweb.org/anthology/E14-1056.pdf)
由上图可知,这些方法与人工判别的结果在大部分结果上还是很一致的,只有部分结果(PMI 等)没能得到很好的一致性。
4. 展望与总结
本文主要介绍了主题模型存在的一些问题和当前比较流行的主题模型评价方法,也对主流的主题模型评价方法进行了简单的分类。
对于未来,我主要有两点想法,一是要适应时代的发展,也就是当前越来越多的数据集和越来越多的小数据集的学习模型,如何更好的利用这些数据集,或者如何找到合适的小数据集的处理方式都是很不错的尝试方向,甚至直接使用监督模型来对主题模型进行评价都可以;第二个就是要时刻记得本质问题,这也是为什么我要在文章的第一节就提出主题模型常见错误的原因,评价方法的本质还是为了找到这些错误,站在这些专家的肩膀上,我们可以把这些常见错误分而治之,利用不同的模型解决不同的错误,或是如何找到这些错误的共同特点,从而完成一个更加通用的建模,这些都是这个领域可以探索的方向。当然这个领域的未来发展方向还有很多,我在这里也只是抛砖引玉。
希望大家喜欢这种探索的过程!

时间:2020-02-06 22:12 来源:可思数据 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
- [机器学习]4款深度学习框架简介,初学者该如何选择?
- [机器学习]AMD如何应对半路杀出的程咬金?
- [机器学习]神经科学如何影响人工智能?看DeepMind在NeurIPS2
- [机器学习]DeepMind的AlphaFold被刷屏后,圈内科学家是如何“吃
- [机器学习]光刻如何一步一步变成了芯片制造的卡脖子技术
- [机器学习]牛津CS博士小姐姐134页毕业论文探索神经网络内部
- [机器学习]Dynamic ReLU:微软推出提点神器,可能是最好的R
- [机器学习]Dynamic ReLU:微软推出提点神器,可能是最好的R
- [机器学习]如何理解YOLO:YOLO详解
- [机器学习]如何理解YOLO:YOLO详解
相关推荐:
网友评论:















