京东电商推荐系统实践

今天为大家分享下京东电商推荐系统实践方面的经验,主要包括:
-
简介
-
排序模块
-
实时更新
-
召回和首轮排序
-
实验平台
▌简介
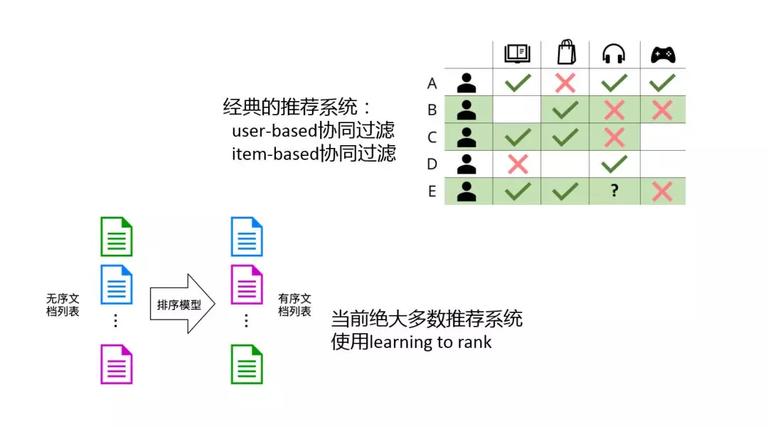
说到推荐系统,最经典的就是协同过滤,上图是一个协同过滤的例子。协同过滤主要分为俩种:user-based 基于用户的协同过滤和 item-based 基于商品的协调过滤。
但是,现在绝大多数推荐系统都不会直接使用协同过滤来做推荐。目前主要用的是 learning to rank 框架。
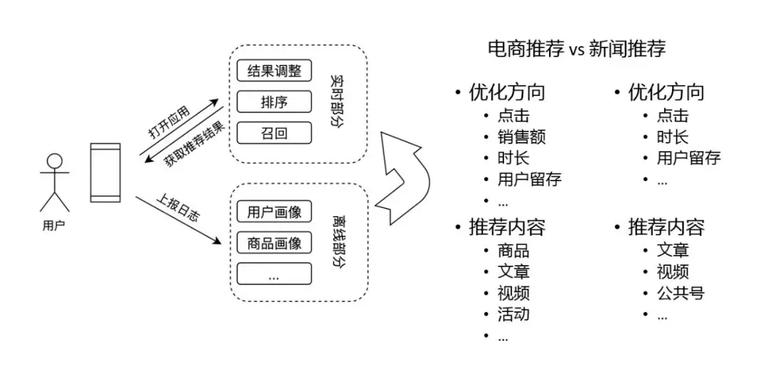
这里,是推荐系统的框架,整个推荐系统可以分为两部分,在线部分和离线部分。
-
在线部分主要负责当用户访问时,如何把结果拼装好,然后返回给用户。主要模块有召回、排序和对结果的调整。
-
离线部分主要是对用户日志的数据分析,应用于线上。
整个推荐系统大概就是这样的一个框架。
和新闻、视频这类的内容推荐相比,电商推荐系统又有一些特殊的地方,比如:
优化方向(点击、销售额、时长、用户留存等)。另外,电商中推荐的内容也会有很多种,尤其像是活动类的内容,很多推荐都是算法和人工运营共同完成的。这就是电商推荐和新闻推荐等的区别之处。
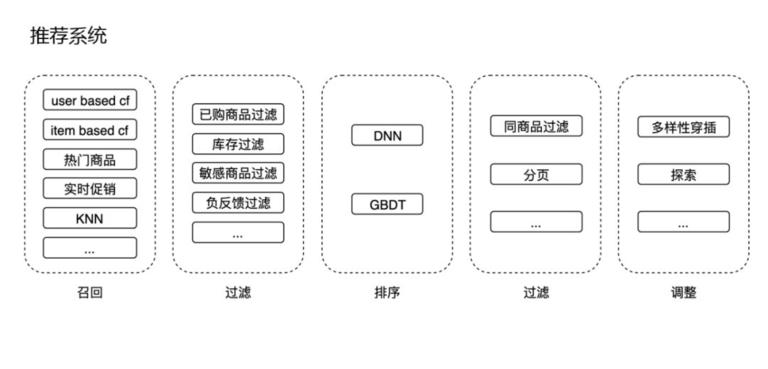
我们展开看下在线推荐系统:
除了刚才说的召回和排序以及最终的调整之外,还有实践过程中的一些细节。
-
召回:这里召回会有很多种方法,如协同过滤,热门商品、实时促销等和应用场景相关的召回,还有一些基于 KNN 的召回。
-
过滤:召回之后,会进行过滤,主要是和应用场景相关,如已购商品过滤掉、没有库存的过滤掉,或者敏感的商品过滤掉等等这些逻辑。
-
排序:排序目前主要用到的是 DNN 模型,某些流量比较小的地方会用到 GBDT。
-
过滤:排序之后还会有些分页、同商品过滤等逻辑。
调整:最终调整过程中,主要有两部分逻辑,多样性和探索逻辑。
▌排序模块
1. 模型结构
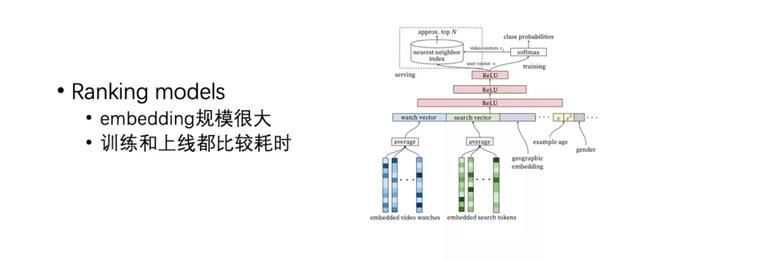
深度学习 ranking 模型结构我们不作为重点讨论,这里列举了一种最经典的模型,它们都用到了很多 id 的 Embedding,然后这些 Embedding 规模都很大,这样训练和上线都比较耗时。因此,我们做了一些优化,比如做分布式的训练,并且会有一套 Pipeline 来完成模型的上线。另外,虽然模型很复杂,并且能带来很好的效果,但是特征工程还是必不可少的,很多指标的提升还是依赖于特征工程,当然也包括一些模型调整的工作。
2. 实践
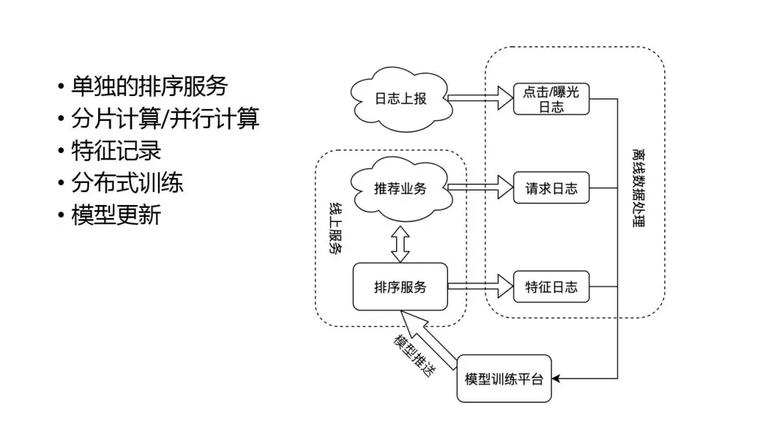
那么如何把这些模型落地呢?我们看下整个模型的上线过程:
首先最重要的部分是模型训练平台和排序服务,因为很多深度模型计算量要求很高,为了能达到比较快的效果,需要部署单独的排序服务。目前比较流行的是 TensorFlow serving,可以很快速的来上线一个深度模型,并充分利用对分片、单机并行,达到很高的计算效率。
模型线上线下一致性问题对于模型效果非常重要,我们使用特征日志来实时记录特征,保证特征的一致性。这样离线处理的时候会把实时的用户反馈,和特征日志做一个结合生成训练样本,然后更新到模型训练平台上,平台更新之后在推送到线上,这样整个排序形成了一个闭环。
3. 实时更新

我们的特征和模型都需要做实时的更新。因为我们经常需要很快的 catch 一些实时的信号,比如需要实时的用户画像来抓住实时的用户兴趣的变化,还比如需要抓住实时的商品画像,因为经常会有一些活动或者爆品,我们需要快速的捕捉这些信号,并应用到推荐中。另外还有一些实时的召回和特征,比如一些交叉的特征,实时的点击率,实时订单等特征。
除了特征外,模型也需要实时更新,对于电商场景来说这是有一定困难的,因为订单是有延时的,延时可能是十几分钟到十几小时不等,这样实时模型更新上就会采取一些保守的策略,比如用点击率对模型做些微调,然后订单数据再通过离线来获得,这属于业务场景的限制。
▌思考
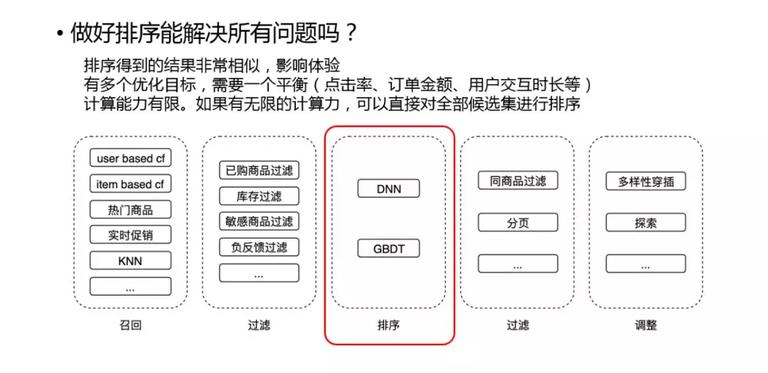
排序可以算是推荐系统中比较重要的一个环节,但是只有排序肯定是不够的,事实上,有一些问题是目前的排序框架无法解决的:
-
排序得到的结果非常相似,影响体验。
-
有多个优化目标,需要一个平衡(点击率、订单金额、用户交互时长等)。
-
计算能力有限,如果有无限的计算力,可以直接对全部候选集进行排序。
1. 多样性

使用模型输出的结果一般都会非常相似,如果直接给用户看体验会很差,因此在模型之后我们需要加入多样性的逻辑。
比较通用的解决办法是多样性的 ranking,这是一个贪心算法,从第一个商品开始选,当选第二个商品的时候,会重新计算下候选集中每个商品的 score,然后选择一个 score 最高的。我们的方法是看 novelty score 候选商品的产品词分布和之前 N 个商品的产品词分布的 KL 距离。这样做的思路,就是选一个和已有商品最不像的商品,来更好的保证商品推荐结果的多样性。
由于纯基于算法的多样性可能会出现 badcase,因此还需要一个规则来进行兜底,确保在极端情况下结果也能接受。
最后,我们思考一个问题,有没有更好的方法实现多样性的逻辑呢?当然有,比如是否可以考虑使用 list wise ranking。这里只是为大家分享一个比较容易的,并且效果比较好的方法。
2. 多目标
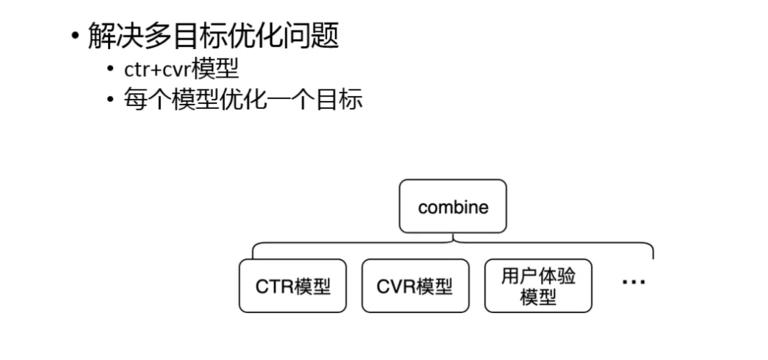
我们的优化目标有很多,比如点击、转化、时长等,问题会变得比较复杂,单一的模型训练很难覆盖到所有指标。另外,经常我们需要在各个指标之间进行权衡,因此可调试性也非常重要。
一种很有用的方式是多模型 ranking,然后用某种方式把所有模型的结果 combine。
这也体现了一个思想,在算法的实际应用中,其实需要在算法的先进性和系统可维护性、可调试性之间做一个平衡。往往 paper 里很有创意的算法落地的时候是有些困难的。
3. 多轮排序
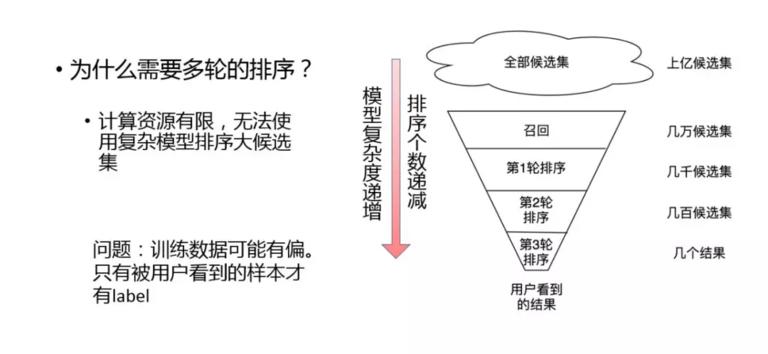
下面我们讨论一下多轮排序的问题。多轮排序是 learning to rank 实践中很重要的一个思想。使用多轮排序主要是因为计算资源的限制,无法使用复杂的模型进行大规模的候选集排序。右图描述了一个多轮排序的框架。这像是一个漏斗模型,从上往下模型的复杂度是递增的,同时候选集是逐渐减少的,就是越到后面用越复杂的模型来保证效果更好,越到前面可能只需要简单的模型来保证能拿到一些商品就可以了。
这样会存在一个问题,由于训练样本可能有偏,导致只有被用户看到的样本才有 label,但是一般不会有太大的影响。
▌基于索引的首轮排序
1. 索引召回
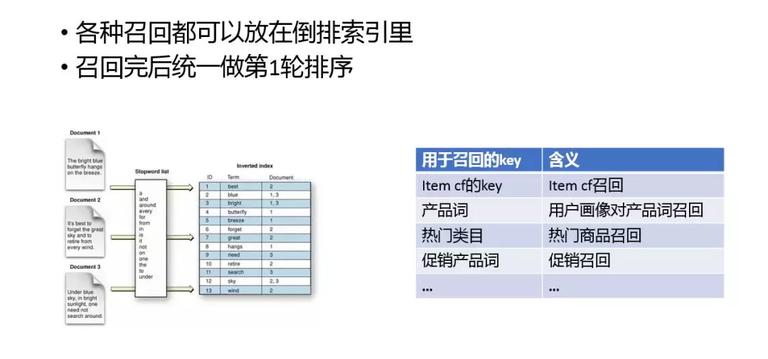
下面我们重点介绍一下第一轮排序。倒排索引很常见,是信息检索里常用的工具。它通过把 doc 的内容索引到 doc id 的方式,快速通过内容来查找 doc。我们很多召回都是通过索引实现的。这里我列举了一些基于索引的召回方式,如 item cf 的 key、产品词、热门类目、促销产品词等。

虽然索引能够很大程度上的缩小候选集的范围,但是经常情况下,第一轮排序的 doc 数量仍然可能会很大。为了保证性能,截断逻辑是必不可少的。通过情况下可以通过 quality score 截断,保留质量好的 doc。经过线性的 LR 或者 GBDT 模型就可以有结果了。另外截断之后需要有些多样性的逻辑,因为只有在召回的时候保持多样性,最终结果才会有多样性。

基于 quality score 截断是一种 naive 的算法,这里我们讨论另一种业界也较常用的算法,wand。wand 其实是 weak and,它的重点是 wand 操作符。wand 操作符是一个布尔操作符,当 Xi wi 比 θ 大时,它的值是 1,否则是 0。之所以叫做 weak-and,是因为当 w 都取 1, θ 取 K 时,wand 操作符就变成了 and,当 w 取 1,θ 取 1 时,wand 操作符就变成了 or。可以看出 wand 是介于 and 和 or 之间的操作。对 Xi wi 求和的操作其实和我们线性模型很相似。通过 wand 操作符,我们可以定义一些上界,因为是倒排索引,可以给每个索引链赋予一个估计值,这样就可以拿到权重上界 UBt,这样通过和 wand 操作符对比,就可以快速的判断 UBt 是否满足条件,如果满足条件就可以快速的把一些 doc 扔掉,这样就可以快速的使用线性模型对全户做 ranking。可以看到,基于线性模型的分数做截断,比完全基于 quality score 截断的策略要稍微好一点。

这里我列了 paper 中 wand 算法的伪代码。出于时间关系,我们不会过算法逻辑的细节。我认为它的主要的思路是通过快速使用 upper bound 做截断和跳转,可以略过很多明显不符合的候选 doc,从而减少计算 score 的次数。当然这种方法对于线性模型来说,有一个缺点,当我们需要多样性的时候,没办法很好的实现在模型中增加多样性的。
wand 算法目前已经应用非常广泛了,在很多开源的索引如 lucene 中,也会用到这种方法快速计算文本相关分。

刚刚我们介绍了使用倒排索引做第一轮排序,以及一个常见的排序加速算法,回过来我们思考一下倒排索引本身,它适用于什么场景,不适用于什么场景。
首先它适用于 kv 查找这种场景,并且 kv 查找也属于实际应用很多的情况。但是对于更复杂的方式,类似 graph 的召回方式不友好,比如找用户看过的商品中相似商品的相关商品,这时实现起来会比较麻烦,这是它的一些限制。再一个,我们需要有较好的截断策略,例如底层使用 relevence score 截断,排序使用 GBDT。
当然,索引还会受到机器本身的内存限制,限于机器的大小,很多时候我们需要多机分片部署索引,这样会带来一定的复杂性。虽然有些限制,但是索引是目前应用很广泛、有效的方式,包括在推荐、搜索等领域都会使用到。
2. KNN 召回

除了索引召回,KNN 也是现在较常用的一种召回方式。首先,我们把所有的候选集转换成 embedding,我们把用户兴趣也可以转换成 embedding,通过定义 embedding 之间距离计算公式,我们可以定义 KNN 召回问题,也就是在全部候选池中,找到与用户最接近的 k 个结果。
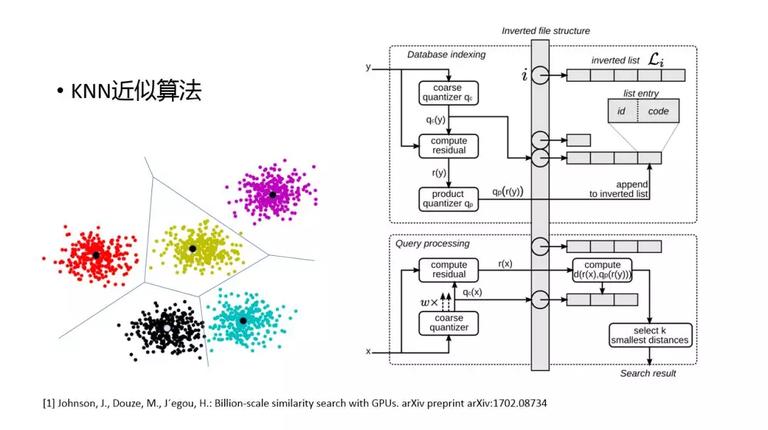
定义好 KNN 召回的问题,下一步就是如何找到最近的 K 个候选集。由于整个候选集非常大,每次都使用用户的 embedding 去全量计算距离是不现实的,只能使用一种近似算法。我们今天分享其中的一种近似算法。是 facebook 开源的 KNN 计算库 faiss 使用的。其原理:
首先需要对全部候选集进行分块,每一块都会有自己的质心。paper 中使用 Lloyd 算法,将整个空间划分开。分块后,就需要对每一块构建索引,进而通过索引实现快速检索的功能。
右图是索引构建和检索的方法。
上半部分是如何构建索引(这里的优化点是使用了二级索引):首先拿到 y 候选集之后,做一个 quantizer 分类得到一个一级索引,把它放到索引表中,另外还得到残差 compute residual,可以对残差再进行一次 quantizer,得到一个二级索引,通过两级索引来加快检索的速度,同理,在真正的 quary 的时候,拿到的是用户的向量 x,先做一个 quantizer,得到 k 近邻的一级索引,然后查找 k 个一级索引,同时拿到 k 个二级索引,然后在二级索引中查找,然后这里还有很多加速的算法(这里就不展开了),通过这样一种多层的查询方式来做到加速 K 近邻的算法。
PS:关于 KNN 的一些思考,KNN 是一种有效的方式,但是不是唯一有效的方式。比如之后分享的 TDM,能够比 KNN 更加灵活。
▌实验平台
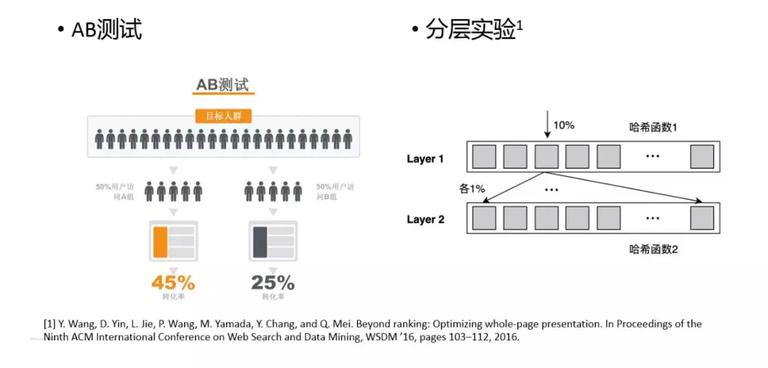
最后简单介绍下分层实验平台,因为大家想快速迭代特征和模型,离不开实验,经常会遇到的情况是实验流量不够用了,这时就需要对实验做分层。分层的逻辑见右图,通过在不同的 Layer 使用不同的哈希函数,保证每个 Layer 之间流量是正交的,这样就可以在不同的 Layer 上做不同的实验。
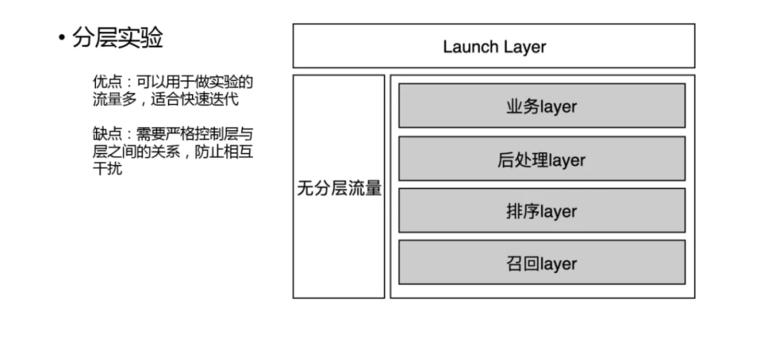
分层实验的具体做法:召回 -> 排序 -> 后处理 -> 业务,另外还有一部分对齐流量,用来做全量的验证。
分层的优点,可以用于做实验的流量多,适合快速迭代;缺点,需要严格控制层与层之间的关系,防止相互干扰。本次分享就到这里,谢谢大家。

嘉宾介绍
孟崇,京东推荐架构负责人。负责京东推荐系统的 ranking 算法架构和模型训练。硕士毕业于中科院自动化所,先后在 yahoo、猎豹移动和京东从事推荐的工作,有丰富的推荐算法经验。
分享嘉宾:孟崇 京东 推荐架构负责人
编辑整理:Hoh Xil
内容来源:DataFun AI Talk
出品社区:DataFun

时间:2019-08-13 11:39 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
相关推荐:
网友评论:















