不平衡数据下的机器学习(上)
1、不平衡学习简介
1.1 数据不平衡与不平衡学习
数据不平衡是机器学习任务中的一个常见问题。真实世界中的分类任务中,各个类别的样本数量往往不是完全平衡的,某一或某些类别的样本数量远少于其他类别的情况经常发生,我们称这些样本数量较少的类别为少数类,与之相对应的数量较多的类别则被称为多数类。在很多存在数据不平衡问题的任务中,我们往往更关注机器学习模型在少数类上的表现,一个典型的例子是制造业等领域的缺陷产品检测任务,在这个任务中,我们希望使用机器学习方法从大量的正常产品中检测出其中少数几个存在缺陷的产品,有缺陷产品在所有产品中的占比可能只有十分之一或者百分之一甚至更低。在这个例子里,我们只关心机器学习模型对少数类(有缺陷产品)的查准率和查全率,并不在意模型在多数类(正常产品)上的表现。
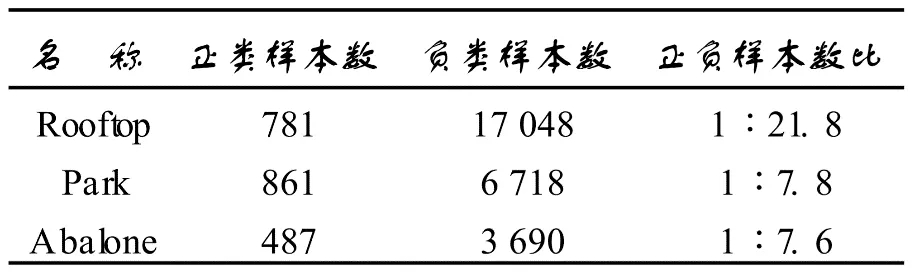
图 1.1 几个存在数据不平衡情况的数据集
图 1.1给出了几个存在数据不平衡情况的数据集。其中,Rooftop是计算机视觉领域的场景识别数据集,正例为包含屋顶的图片;Park是生物信息学领域的模式分类数据集,包含蛋白质亚细胞定位数据;Abalone是鲍鱼年龄识别数据集。
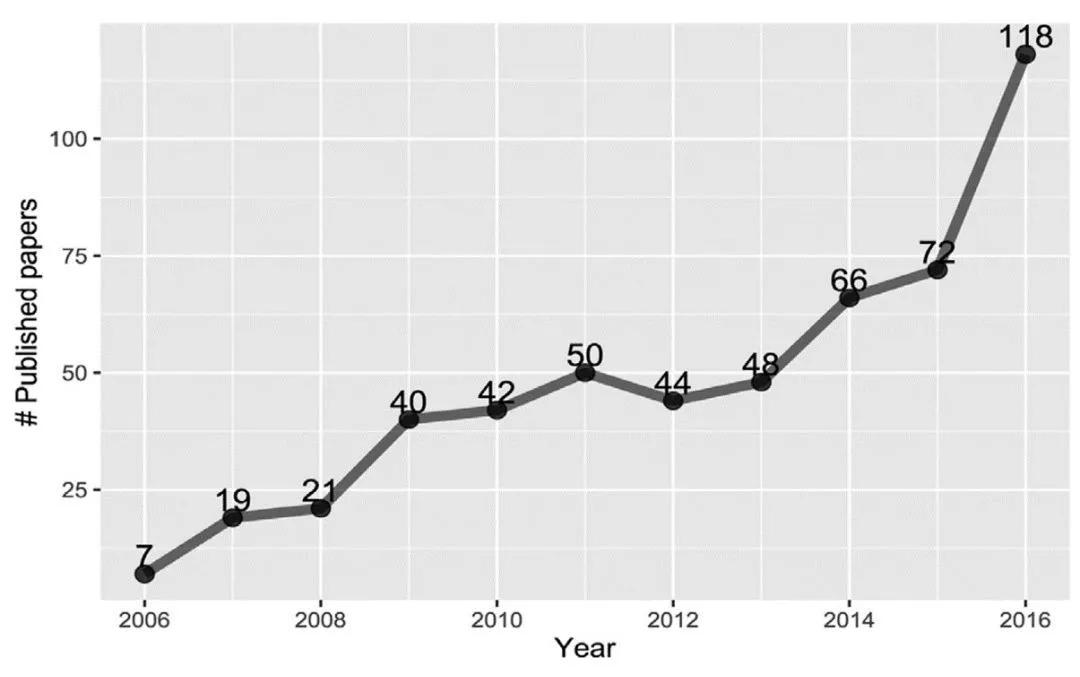
图 1.2 不平衡学习的研究热度逐年增长
数据不平衡为机器学习任务带来了诸多挑战,针对这一问题,业界已经做了诸多研究,方向包括数据不平衡导致机器学习模型性能下降的原因、评估方法和解决方案等。针对数据不平衡问题的研究专题可以统称为不平衡学习(Imbalanced Learning),Guo, H.等人统计了2006年到2016年不平衡学习领域每年的论文发表数量,发现这一数量呈逐年上升的趋势,这说明不平衡学习越来越受到研究社区的关注。
本文主要关注在分类任务下的不平衡学习问题,主要包含以下部分:
第一部分,介绍什么是数据不平衡问题以及为什么要研究数据不平衡问题,数据不平衡又会给机器学习模型分类性能带来什么样的损害。
第二部分,介绍如何有效的评估在不平衡数据下的分类器分类表现,给出几种典型的评估方法。
第三部分,对常见的针对数据不平衡问题的解决方案/算法做归纳介绍以及几种常见算法在实际应用的应用效果比较。
第四部分,关注前沿进展,介绍2篇计算机视觉和自然语言处理领域的不平衡学习研究论文。
1.2 数据不平衡对分类器性能的损害
上一小节已经介绍了数据不平衡问题和由此引发的不平衡学习研究,可能有读者会疑惑为什么要专门针对数据不平衡问题做研究,这一节将介绍数据不平衡是如何对分类器性能造成损害的,不平衡学习的主要研究目的就是希望通过对数据和算法等的改进来消除或减弱数据不均衡对分类器性能的不利影响。
1)数据稀疏问题
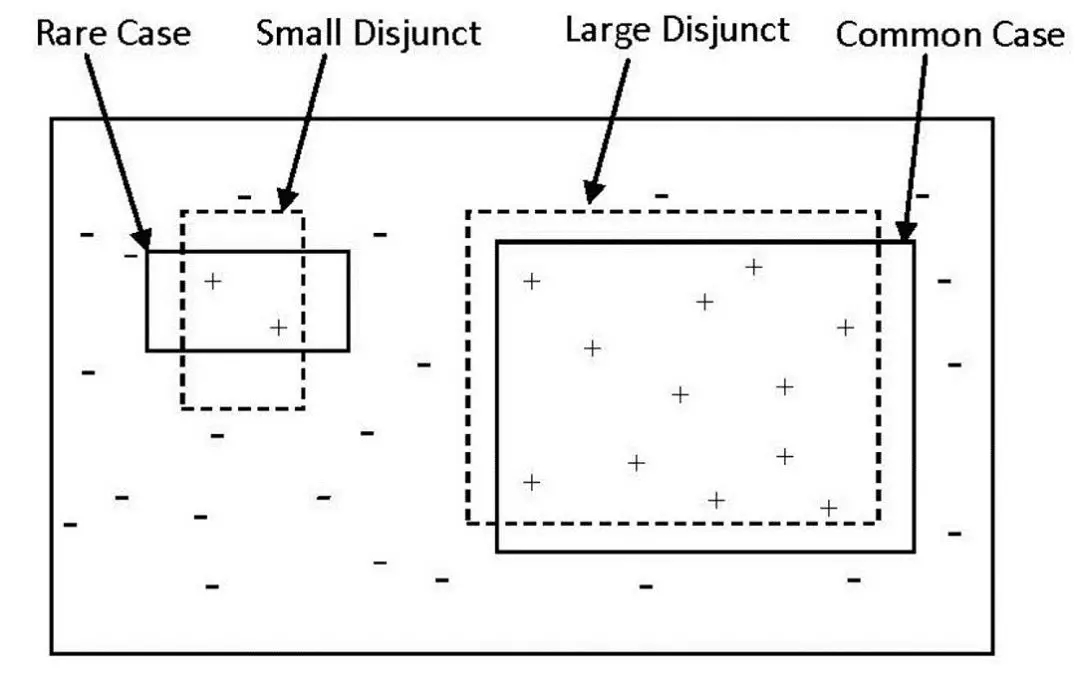
图 1.3 数据稀疏问题
在数据不平衡的情况下,少数类样本的数量远少于多数类样本,会产生更多的稀疏样本(那些样本数很少的子类中的样本)。由于缺乏足够的数据,分类器对稀疏样本的刻画能力不足,难以有效的对这些稀疏样本进行分类。
图 1.3给出了一个决策树分类的例子,+/-分别代表了2类数据,实线框为理想的决策区域,虚线框则为实际的决策区域。对于稀疏样本(左侧少量+类样本),决策区域的少许偏移就会导致较高的分类错误率,从图中可以看到,同样的决策区域的少许偏移,导致稀疏样本部分出现了接近50%的错误率,而非稀疏样本的只有10%左右。
2)数据噪声问题
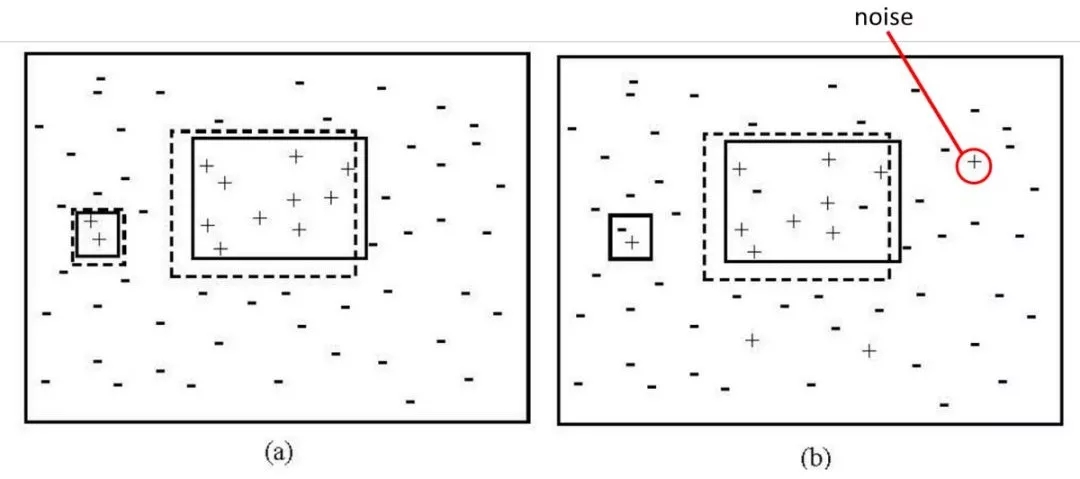
图 1.4 噪声数据问题
在考虑数据噪声的情况下,1)中所述的稀疏样本可能会导致更多的问题,少量的噪声数据就可能对稀疏样本的分类造成较大的影响。同样以决策树分类为例,图 1.4给出的为在数据不包含噪声和包含噪声两种情况下的决策区域变化,可以看到,数据噪声使得稀疏样本子类样本数从2变为1,不满足决策树分支的生成条件(分支下样本数大于等于2),导致了稀疏样本对应的决策区域消失,分类器无法对这一子类的稀疏样本分类。
3)决策边界偏移问题
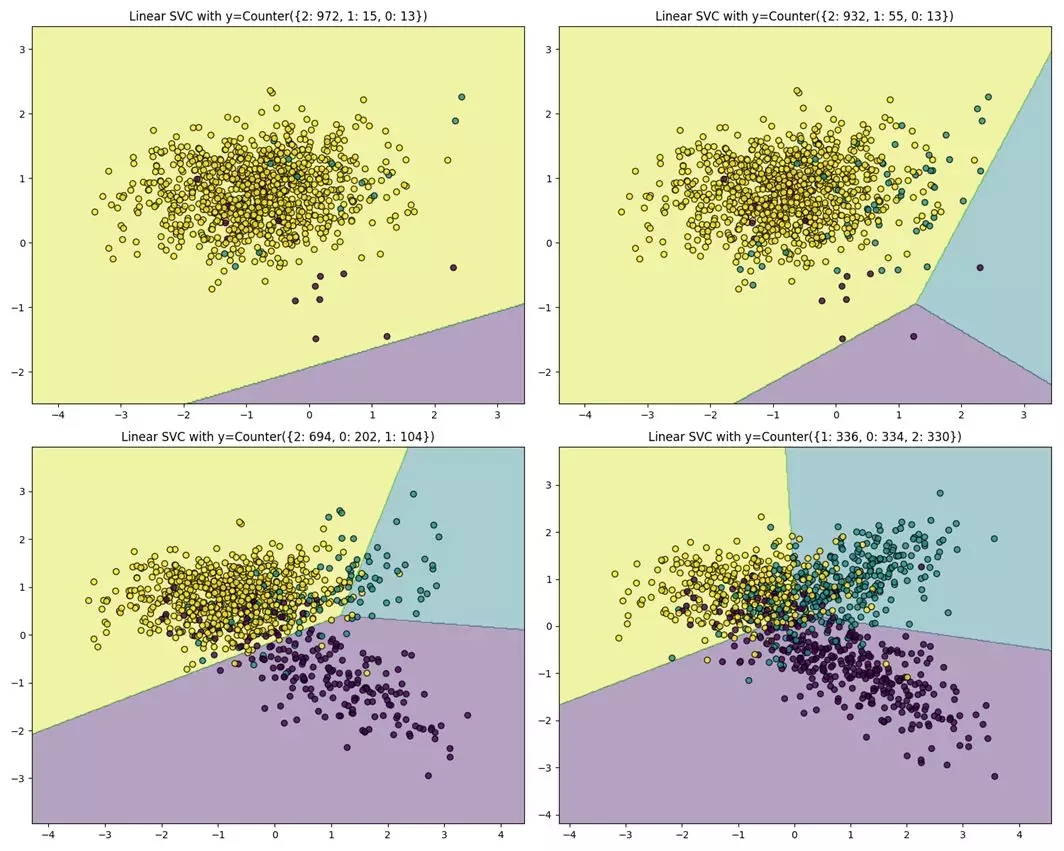
图 1.5 决策边界偏移问题
1)和2)都是从数据的角度看数据不平衡对分类效果的影响。从分类器的角度来看,数据不均衡导致的分类器决策边界偏移也会影响到最终的分类效果。这里以SVM为例:
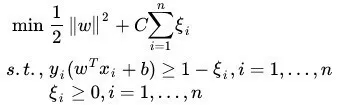
上式给出了SVM的优化目标,少数类和多数类的每个样本对优化目标的贡献都是相同的,但由于多数类样本的样本数量远多于少数类,最终学习到的分类边界往往更倾向于多数类,导致分类边界偏移的问题。图 1.5给出了在一个三分类问题中,不同的数据不平衡程度对应的分类器分类效果示意。从图中可以看出,随着数据不平衡程度的增加,分类器分类边界偏移也逐渐增加,导致最终分类性能下降明显。
2、不平衡数据集的评估方法
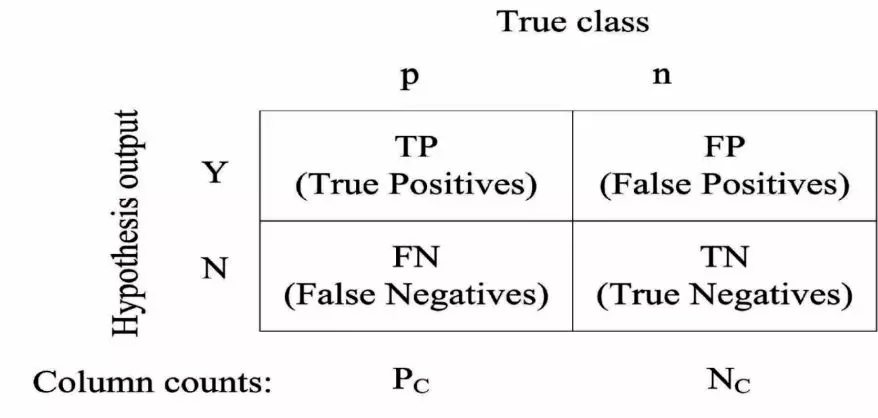
对于平衡数据集,在评估分类效果时,可以使用accuracy作为分类器的性能指标衡量,回顾下accuracy的计算方法,以二分类为例:
混淆矩阵:
Accuracy:
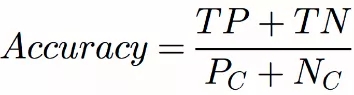
可以看到,在计算accuracy时,TP和TN是完全等价的,即每个类别的样本对accuracy的贡献是相同的,在数据不均衡的情况下,accuracy难以体现模型对少数类的分类效果,不适合直接使用。
对于不平衡数据集,常见的评估方法包括:
1)precision, recall和F值,计算方法如下:
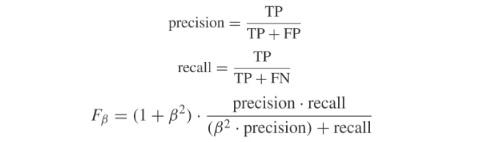
相对于accuracy来说,在数据不平衡的情况下,precision, recall和F值不会受到数据分布的影响,可以更有效的反应分类模型在特定类别上,尤其是少数类上的分类性能。
2)ROC曲线和ROC AUC

图 2.1 ROC曲线
ROC 曲线(接收者操作特征曲线)是一种显示分类模型在所有分类阈值下的效果的图表,图中TP_rate=TP/(TP+FN),FP_rate=FP/(FP+TN)。图 2.1给出了ROC曲线的示意图。我们使用ROC曲线来比较多个分类器的分类性能,上图中L2对应的分类器明显优于L1对应的分类器。
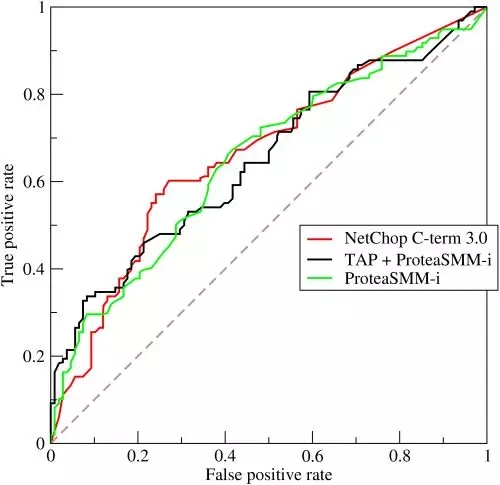
图 2.2 实际的ROC曲线
但实际情况往往更加复杂,图 2.2给出了实际任务中3个分类器的ROC曲线,从ROC曲线上已经难以判断分类器的性能优劣。这时候可以使用ROC AUC(ROC曲线下面积)作为评估指标。ROC AUC测量的是从 (0,0) 到 (1,1) 之间整个 ROC 曲线以下的整个二维面积,AUC越大,对应的分类器性能越接近理想分类器。
3) P/R/F评价指标和ROC AUC只关注模型在单个类别下的分类性能,对于数据不平衡下的多分类任务,可以使用多个分类F值或ROC AUC的宏平均作为最终的评价指标。
3、不平衡学习算法
上两节分别介绍了数据不平衡问题定义、影响和评价指标。本节将开始介绍在机器学习任务中,如何应对数据不平衡问题。
针对数据不平衡问题,现在已经发展出了诸多不平衡学习算法,按照解决思路的不同,可以将这些算法分为以下几类:
采样方法
代价敏感型方法
集成学习方法
主动学习方法
其他
例如Kernel-Based等对分类器算法做修改的方法。
由于时间和篇幅限制,本节不会对这些算法的做非常深入的介绍,将仅对每一类方法做概述,并介绍其中部分经典算法,如果有读者希望深入学习或研究,可以参阅本文文末的参考文献[1-6]或其他参考资料。
3.1 采样方法
采样(Sampling)方法通过特定的对数据采样的方式(例如过采样、降采样和合成采样等)改变数据集的数据分布,使得数据集中不同类别的数据分布较为均衡,从而改善数据不平衡问题。采样方法中的常见算法可以分为3类:
1)随机采样算法:包括随机过采样(Oversampling)和随机降采样(Undersampling)等;
2)合成采样算法:其中包括SMOTE,Border-line-SMOTE, ADASYN, SMOTE+Tomek, OSS等;
3)基于聚类的采样算法:例如CBO等。
随机采样是在机器学习任务中处理数据不均衡问题最常见也最通用的算法,其中,随机过采样和随机降采样的算法流程描述分别如图 3.1和图 3.2所示:
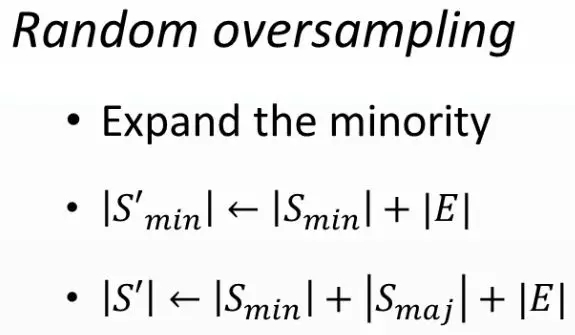
图 3.1 随机过采样

图 3.2 随机降采样
图中,S为训练样本集,Smin为少数类样本集,Smax为多数类样本集,E为随机生成或随机去除的样本集。
随机过采样算法首先对数据集中的少数类样本做随机采样,然后将采样出的样本加入数据集,并多次重复以上流程,得到数据分布更加平衡的数据集。
随机降采样算法首先对数据集中的多数类样本做随机采样,然后将采样出的样本移出数据集,并多次重复以上流程,得到数据分布更加平衡的数据集。
随机过采样和随机降采样都可以平衡数据集样本类别分布,有利于缓解数据不平衡问题。但过采样会将数据集中的少数类样本重复多次,易导致模型出现过拟合;降采样则会去除数据集中部分样本,导致信息损失问题。
合成采样方法是对随机采样方法的改进,最经典的合成采样算法是NV Chawla等人在2002年提出的SMOTE(Synthetic Minority Oversampling Technique)算法,对该算法的描述如图 3.3所示。
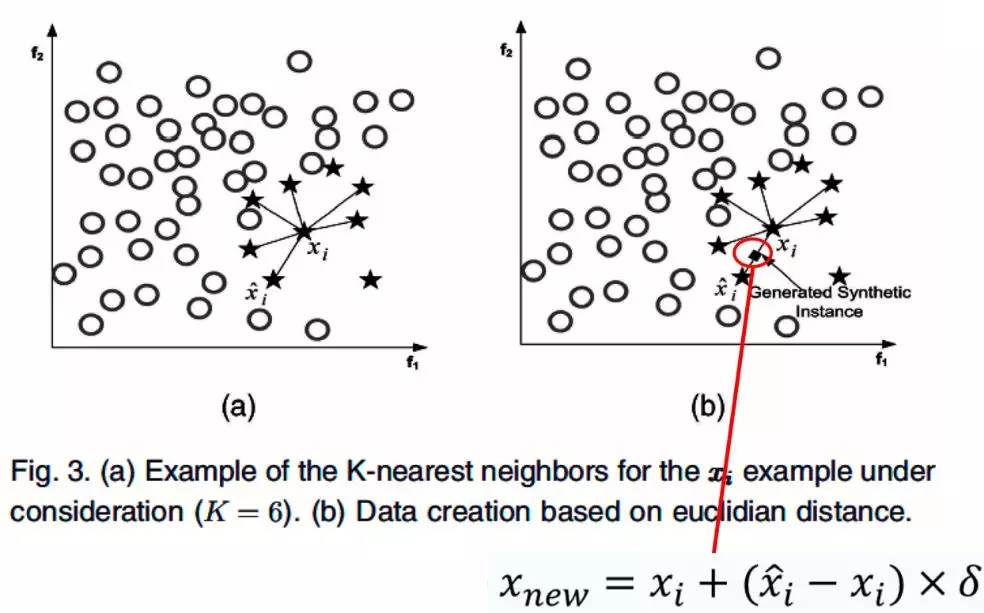
图 3.3 SMOTE算法
SMOTE算法是通过从少数类中随机选取2个样本,然后使用这2个样本作为基样本合成新的样本,一定程度上可以弥补随机过采样的缺陷,但在合成过程中可能会生成大量无效或者低价值样本。已经有很多基于SMOTE的改进算法,例如Border-line-SMOTE, ADASYN, SMOTE+Tomek, OSS等。以Border-line-SMOTE为例,其算法描述如图 3.4所示。
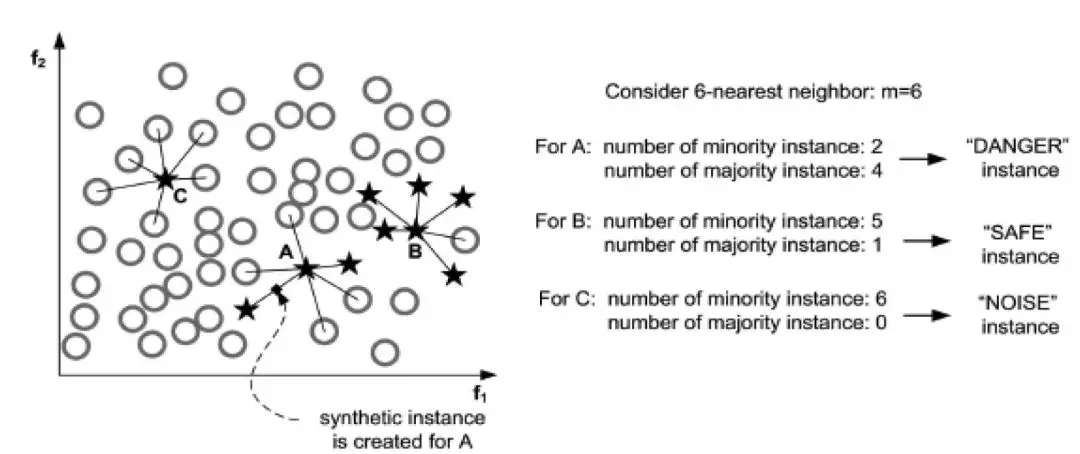
图 3.4 Border-line SMOTE
Border-line SMOTE对原始SMOTE算法的改进主要体现在对基样本的选择上,通过优先选择分类边界附近样本作为基样本的方法来提升合成样本的价值。
除了合成采样,还可以加入聚类的方法来改进随机采样算法,一种CBO(Cluster-based Oversampling)算法如图 3.5所示。
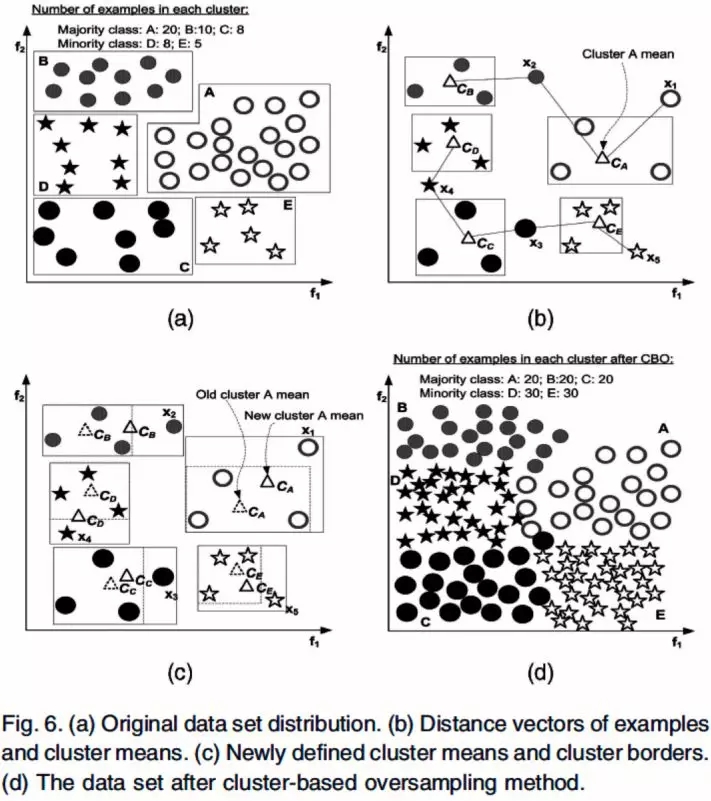
图 3.5 CBO算法

3.2 代价敏感型方法
代价敏感型(Cost-Sensitive)方法通过改变在模型训练过程中,不同类别样本分类错误时候的代价值来获得具有一定数据倾向性的分类模型,这里仍然以SVM为例,原始的目标函数如下式所示:
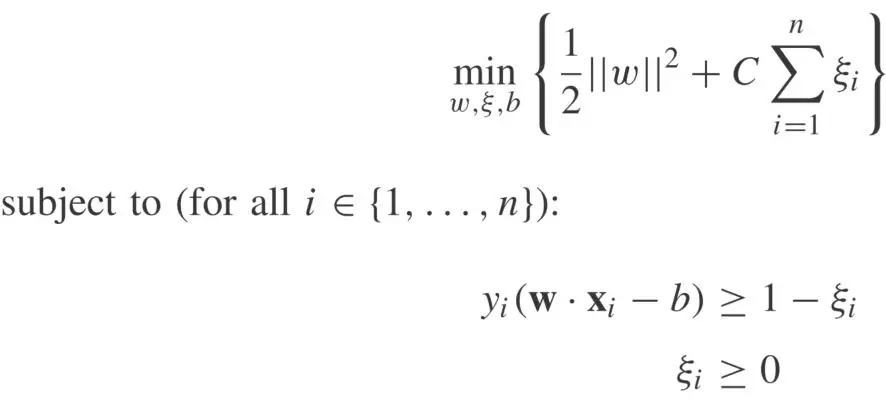
加入代价敏感型方法之后,上式变为:
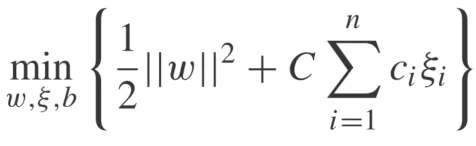
式中ci为第i个样本的代价权重。在数据不平衡的任务中,可以提高少数类的代价权重,获得更倾向于少数类样本的分类器。
常见的代价敏感型方法有MetaCost, AdaCost, Adaptive Scaling等,本文第四节将对Adaptive Scaling方法做详细介绍。
3.3 集成学习方法
集成学习(Ensemble)是一种通过多分类器融合来获取更强分类性能的方法,将上两小节所述采样方法和代价敏感方法与之结合可以获得多种基于集成学习的数据不平衡下的学习算法,按照集成学习方法的不同,可以分为以下三类:
1)基于Bagging的方法。主要思想是将采样方法应用到Bagging算法的抽样过程中,具体操作时一般是首先从不均衡数据中抽取多个均衡子数据集,分别训练多个分类器,然后做Bagging模型集成。主要算法包括OverBagging, UnderBagging, UnderOverBagging, IIVotes等。
2)基于Boosting的方法。主要思想是将Boosting方法与采样方法或代价敏感型方法结合使用,因此又可以分为2小类:
a)代价敏感+Boosting: Boosting过程中更改类别权重,迭代时更关注少数类样本。主要算法包括AdaCost, CSB1, CSB2, RareBoost, AdaC1等。
b)采样方法+Boosting: Boosting过程中更改样本分布,迭代时更关注少数类样本。主要算法包括SMOTEBoost, MSMOTEBoost, RUSBoost, DataBoost-IM等。
3)Hybrid方法,即将基于Bagging的方法和基于Boosting的方法结合使用,主要算法包括EsayEnsemble和BalanceCascade等。
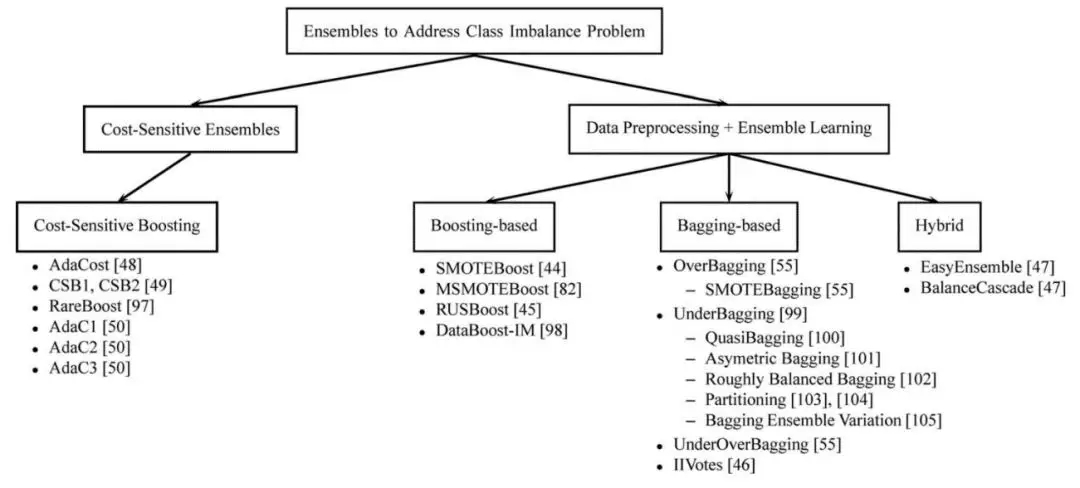
图 3.6 用于解决数据不平衡问题的集成学习方法
图 3.6是Galar, M.等人对用于解决数据不平衡问题的集成学习方法的总结。对集成学习+不平衡学习感兴趣的读者可以阅读参考文献[4],本文不再针对具体算法做详述。
3.4 主动学习方法
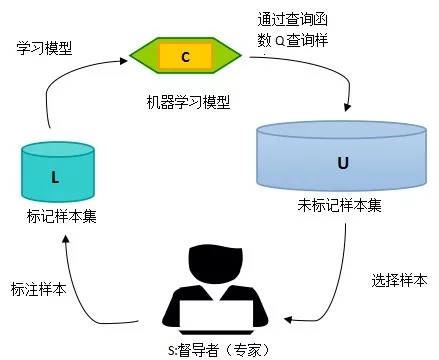
图 3.7 主动学习
前面三小节的方法都是在数据集已经标注完成的基础上,通过优化数据处理方法或优化机器学习算法来提升模型在不平衡数据集上的分类性能。本小节所述的主动学习(Active Learning)方法则更关注于数据标注过程,将数据标注与模型训练迭代进行,每轮迭代在完成模型训练之后,通过一定的算法查询最有用的未标记样本,并交由专家进行标记,然后用查询到的样本重新训练分类模型来提高模型的较精确度。
图 3.7给出了主动学习流程的示意图。
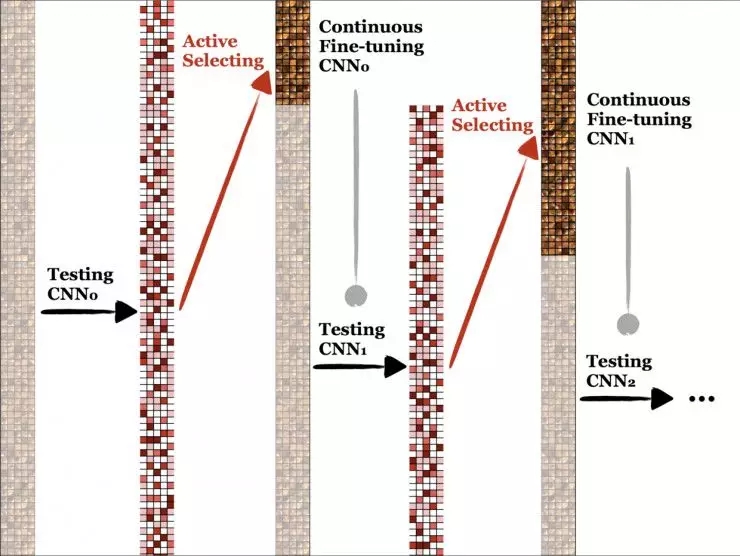
图 3.8 主动学习示例
图 3.8则给出了一个将主动学习方法应用于CNN图像识别的例子,其具体流程可以描述如下:
1)标注少量训练数据,使用这少量数据训练分类模型;
2)使用训练好的模型对未标注数据进行预测;
3)根据预测结果,从样本多样性和分类难度上评判样本信息量,选择其中信息量较大的样本做人工标注;
4)加入新标注数据重新训练模型;
5)重复2-5步,直到数据标注数量或模型性能满足要求。
按照对样本信息量评判方法的不同,主动学习算法可以分为以下2类:
1)基于不确定性的方法,例如uncertainty sampling, margin-base方法等
2)基于多分类器投票的方法,例如qbc, co-testing等
接下来我们关注一下如何将主动学习方法应用于数据不平衡问题,Li, S.等在在2012年提出了一种将主动学习方法应用在不平衡情感分类任务上的方法:co-selecting,其算法流程描述如图 3.9所示:

图 3.9 co-selecting主动学习方法
其算法的核心就是使用2个没有交叠的特征集分别训练2个分类器,使用第一个分类器筛选等量的分类置信度较高的正负例样本,然后再使用第二个分类器筛选出其中分类置信度较低的样本,经过两轮筛选同时保证了新的待标注数据的数据平衡和信息量。
来自: 哈工大讯飞联合实验室

时间:2019-06-05 23:40 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
- [机器学习]堪比当年的LSTM,Transformer引燃机器学习圈:它是
- [机器学习]论机器学习领域的内卷:不读PhD,我配不配找工
- [机器学习]机器学习基础图表:概念、原理、历史、趋势和算法
- [机器学习]分析了 600 多种烘焙配方,机器学习开发出新品
- [机器学习]2021年的机器学习生命周期
- [机器学习]物联网和机器学习促进企业业务发展的5种方式
- [机器学习]机器学习中分类任务的常用评估指标和Python代码实现
- [机器学习]机器学习和深度学习的区别是什么?
- [机器学习]堪比当年的LSTM,Transformer引燃机器学习圈:它是
- [机器学习]年终总结:2021年五大人工智能(AI)和机器学习(ML)发展趋势
相关推荐:
网友评论:















