LSTM 原理与实践,原来如此简单
目录
–

一、介绍
1.1 LSTM 介绍
LSTM 全称 _Long Short-Term Memory_,是 1997 年就被发明出来的算法,作者是谁说了估计也记不住干脆就不说了(主要是我记不住,逃…)
经过这么多年的发展,基本上没有什么理论创新,唯一值得说的一点也就是加入了 Dropout 来对抗过拟合。真的是应了那句话呀:
Deep learning is an art more than a science.
怪不得学数学的一直看不起搞算法的,不怪人家,整天拿着个梯度下降搞来搞去,确实有点 low。。。
即使这样,LSTM 的应用依旧非常的广泛,而且效果还不错。但是,LSTM 的原理稍显复杂,苦于没有找到非常好的资料,小编之前也是被各种博客绕的团团转,今天重新梳理了一次,发现并没有那么难,这里把总结的资料分享给大家。
认真阅读本文,你将学到:
RNN 原理、应用背景、缺点
LSTM 产生原因、原理,以及关于 LSTM 各种“门”的一些 intuition(哲学解释) (别怕,包教包会)
如何利用 Keras 使用 LSTM 来解决实际问题
关于 Recurrent Network 的一些常用技巧,包括:过拟合,stack rnn
1.2 应用背景
Recurrent network 的应用主要如下两部分:
-
文本相关。主要应用于自然语言处理(NLP)、对话系统、情感分析、机器翻译等等领域,Google 翻译用的就是一个 7-8 层的 LSTM 模型。
-
时序相关。就是时序预测问题(timeseries),诸如预测天气、温度、包括个人认为根本不可行的但是很多人依旧在做的预测股票价格问题
这些问题都有一个共同点,就是有先后顺序的概念的。举个例子:
根据前 5 天每个小时的温度,来预测接下来 1 个小时的温度。典型的时序问题,温度是从 5 天前,一小时一小时的记录到现在的,它们的顺序不能改变,否则含义就发生了变化;再比如情感分析中,判断一个人写的一篇文章或者说的一句话,它是积极地(positive),还是消极的(negative),这个人说的话写的文章,里面每个字都是有顺序的,不能随意改变,否则含义就不同了。
全连接网络 Fully-Connected Network,或者卷积神经网络 Convnet,他们在处理一个 sequence(比如一个人写的一条影评),或者一个 timeseries of data points(比如连续 1 个月记录的温度)的时候,他们缺乏记忆。一条影评里的每一个字经过 word embedding 后,被当成了一个独立的个体输入到网络中;网络不清楚之前的,或者之后的文字是什么。这样的网络,我们称为 feedforward network。
但是实际情况,我们理解一段文字的信息的时候,每个文字并不是独立的,我们的脑海里也有它的上下文。比如当你看到这段文字的时候,你还记得这篇文章开头表达过一些关于 LSTM 的信息;
所以,我们在脑海里维护一些信息,这些信息随着我们的阅读不断的更新,帮助我们来理解我们所看到的每一个字,每一句话。这就是 RNN 的做法:维护一些中间状态信息。
二、SimpleRNN
2.1 原理
RNN 是 Recurrent Neural Network 的缩写,它就是实现了我们来维护中间信息,记录之前看到信息这样最简单的一个概念的模型。
关于名称,你可以这样理解:Recurrent Neural Network = A network with a loop. 如图:
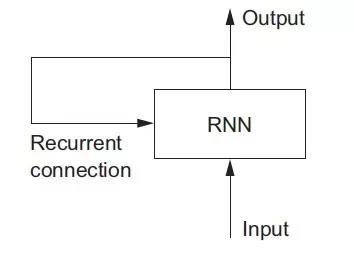
为了更清楚的说明 _loop_ 和 _state_,我们来实现一个简单的 toy-rnn。输入是 2 维的(timesteps, input_features).
这里的 _loop_ 就是在 _timesteps_ 上的 _loop_:每一个时刻 t,RNN 会考虑当前时刻 t 的状态 _state_,以及当前时刻 t 的输入 ( 维度是(input_features,)), 然后总和得到在时刻 t 的输出。并且为当前时刻 t 的输出去更新状态 _state_。但是最初的时刻,没有上一个时刻的输出,所以 state 会被全初始化为 0,叫做 _initial state of the network._
代码如下:
state_t = 0 #时刻t的状态for input_t in input_sequence: # 在timesteps上loop
output_t = f(input_sequence, state_t) # input_t state_t得到时刻t输出
state_t = output_t # 用当前输出去更新内部状态
f是一个函数,它完成从 input 和 state 到 output 的转换,通常包含两个矩阵W, U和一个偏置向量b,然后再经过激活函数激活。形式如下:
f = activation(dot(W, input) + dot(U, state) + b)
非常类似 DNN 中的全连接层。
还不明白看代码:
# SimpleRNN in numpyimport numpy as np
timesteps = 100
input_features = 32
output_features = 64
inputs = np.random.random(shape=(timesteps, input_features))
state_t = np.zeros(shape=(output_features,)) # init state
W = np.random.random(shape=(output_features, input_features))
U = np.random.random(shape=(output_features, output_features))
b = np.random.random(shape=(output_features,))
successive_outputs = []
for input_t in inputs: output_t = np.tanh(np.dot(W, input_t) + np.dot(U, state_t) + b) #input_t state_t => output_t successive_outputs.append(output_t) state_t = output_t# update state_t using output_t
final_outputs = np.concatenate(successive_outputs, axis=0) #get the final_output with shape=(timesteps, output_features)
所以,RNN 其实就是在时间上的一个循环,每次循环都会用到上一次计算的结果,就这么简单。在时间上,把 RNN 展开如下图:
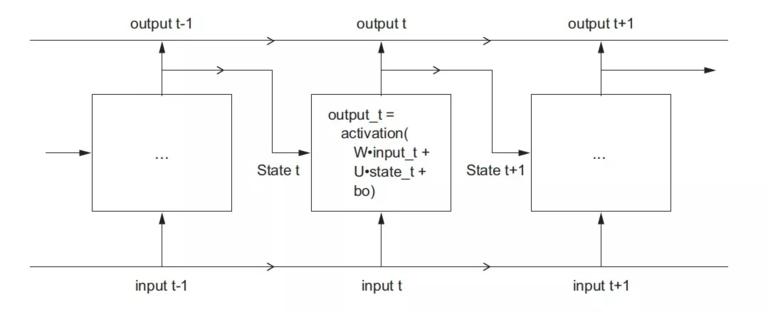
关于输出,虽然 RNN 每个时刻 t 都会有输出,但是最后时刻的输出实际上已经包含了之前所有时刻的信息,所以一般我们只保留最后一个时刻的输出就够了。
2.2 优缺点
-
优点。处理 a sequence 或者 a timeseries of data points 效果比普通的 DNN 要好。中间状态理论上维护了从开头到现在的所有信息;
-
缺点。不能处理 long sequence/timeseries 问题。原因是梯度消失,网络几乎不可训练。所以也只是理论上可以记忆任意长的序列。
三、LSTM
LSTM 就是用来解决 RNN 中梯度消失问题的,从而可以处理 long-term sequences。
3.1 原理
LSTM 是 SimpleRNN 的变体,它解决了梯度消失的问题。怎么解决的那?
LSTM 增加了一个可以相隔多个 timesteps 来传递信息的方法。想想有一个传送带在你处理 sequences 时一起运转。每个时间节点的信息都可以放到传送带上,或者从传送带上拿下来,当然你也可以更新传送带上的信息。这样就保存了很久之前的信息,防止了信息的丢失。我们把 SimpleRNN 中的矩阵记为Wo Uo bo,LSTM 的结构图如下:
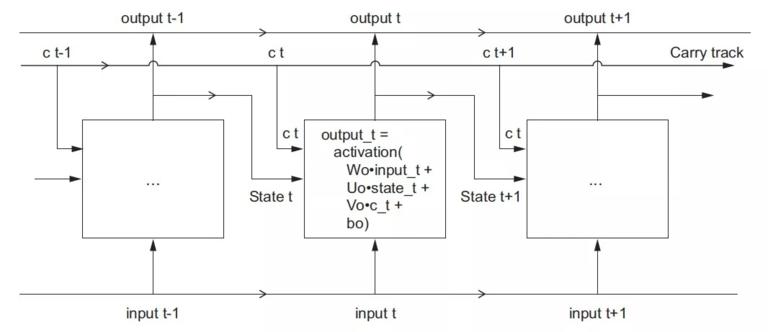
我们在 SimpleRNN 基础上,增加一条传送带(adding a carry track)用来传递信息。传送带上每个时刻的状态我们记为:c t c 是 carry 的意思。
显然,当前时刻的输出就应该收到三个信息的影响:当前时刻的输入、当前时刻的状态、传送带上带来的很久以前的信息。如下:
output_t = activation(dot(state_t, Uo) + dot(input_t, Wo) + dot(C_t, Vo) + bo)
这里的处理方式和 SimpleRNN 是一样的,都是矩阵相乘,矩阵相加,在经过激活函数的操作。
其实当前时刻 t 的输出就解释清楚了。还有一个问题就是两个状态怎么更新那:state_t, C_t.
-
RNN 内部的状态 state_t 还是跟之前一样:用上一个时刻的输出来更新。
-
传送带上的状态更新就是 LSTM 的重点了,也是复杂的地方
根据input_t, state_t以及三套不同的W U b,来计算出三个值:
i_t = activation(dot(state_t, Ui) + dot(input_t, Wi)+ bi)
f_t = activation(dot(state_t, Uf) + dot(input_t, Wf) + bf)
k_t = activation(dot(state_t, Uk) + dot(input_t, Wk) + bk)
然后组合这三个值来更新C_t:
c_t+1 = i_t * k_t + c_t * f_t
用图表示如下:
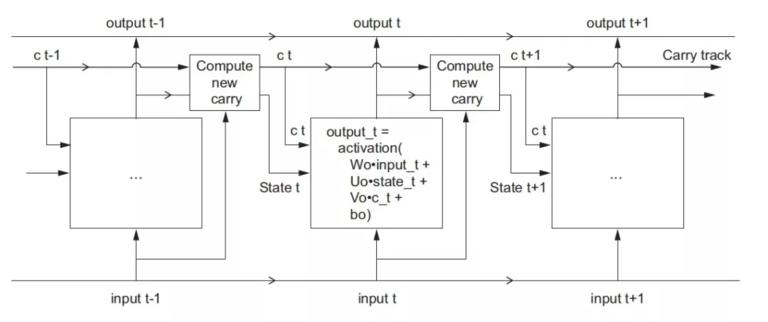
也不是那么复杂嘛,对吧?还不理解看看下节的 _Intuition_ 来帮助你更好的理解,为什么要这样更新 c_t.
3.2 Intuition
这一节解释下为什么要这样更新 c_t, 帮你建立一些 _Intuition_,或者说一些哲学的解释,为什么要这样做。
还记得开篇说的么?
Deep Learning is an art more than a science.
建立关于 DL 模型的一些 _Intuition_ 对于算法工程师是非常重要的。打球还有球感那,搞 DL 没有点 intuition 都不敢说是这一行的。
你可以这样理解上面的操作:
-
c_t * f_t是为了让模型忘记一些不相关的信息,在 carry dataflow 的时候。即时是很久之前的信息,模型也有不用他的选择权利,所以模型要有忘记不相关信息的能力。 这也就是常说的遗忘门(我觉得翻译成中文真的很没意思,因为中文的“门”意思是在是太多了,你懂得)。 -
i_t * k_t为模型提供关于当前时刻的信息,给 carry track 增加一些新的信息。
所以,一个忘记不相关信息,一个增加新的信息,然后再 carry track 向下传递这个 c_t, LSTM 真的没那么复杂,如果你觉得很复杂,就是资料没找对。
补充一点,上面这样解释只是为了帮助大家理解,基本上所有的 LSTM 资料也都是这样解释的。但是,当模型真的训练完成后,所谓的模型就是存储下来的 W U b 矩阵里面的系数。这些系数到底是不是跟我们想的一样的那?没有人知道,也许一样,也许不一样,也许某些问题是这样的,也许某些问题不是这样的。
要不说 DL 是一门艺术那,没有严谨的科学证明,很多时候只是实际应用后发现效果好,大家就觉得是在朝着正确的方向发展。仔细想想,有点可怕,万一方向错了那?就拿 BP 算法来说,人类大脑学习记忆,并没有什么反向传播吧。。。
3.3 优缺点
-
优点。解决了 SimpleRNN 梯度消失的问题,可以处理 long-term sequence
-
缺点。计算复杂度高,想想谷歌翻译也只是 7-8 层 LSTM 就知道了;自己跑代码也有明显的感觉,比较慢。
四、最佳实践指南
4.1 RNN 表达能力
有的时候 RNN 的表达能力有限,为了增加 RNN 的表达能力,我们可以 stack rnn layers 来增加其表达能力。希望大家了解这是一种常用的做法。
当然了,中间的 RNN layer 必须把每个时刻的输出都记录下来,作为后面 RNN 层的输入。实践环节我们会给出例子。
4.2 过拟合
RNN LSTM 同样会过拟合。这个问题直到 2015 年,在博士 Yarin Gal 在他的博士论文里给出了解决办法:类似 dropout。但是在整个 timesteps 上使用同一个固定的 drop mask。
博士大佬发了论文,还帮助 keras 实现了这一举动,我们只需要设置参数dropout, recurrent_dropout就可以了,前者是对输入的 drop_rate, 后者是对 recurrent connection 的 drop_rate。recurrent_connection 就是 stata_t 输入到 SimpleRNN 中的部分。
话说,为啥人家都这么优秀那,嗑盐厉害,工程也这么厉害,是真的秀
4.3 GRU
LSTM 的计算比较慢,所有有了 Gated Recurrent Unit(GRU),你可以认为他是经过特殊优化提速的 LSTM,但是他的表达能力也是受到限制的。
实际使用的时候,从 LSTM 和 GRU 中选一个就行了,SimpleRNN 太简单了,一般不会使用。
4.4 1D-Convnet
另外一种处理 sequence 或者 timeseries 问题的方法就是使用 1 维的卷积网络,并且跟上 1 维度的池化层。卷积或者池化的维度就是 timestep 的维度。它可以学习到一些 local pattern,视它 window 大小而定。
优点就是简单,计算相比于 LSTM 要快很多,所以一种常用的做法就是:
-
用 1D-Convnet 来处理简单的文本问题。
-
把它和 LSTM 融合,利用 1D-Conv 轻量级,计算快的优点来得到低维度特征,然后再用 LSTM 进行学习。这对于处理 long sequence 非常有用,值得尝试。
五、SimpleRNN 与 LSTM 实践
之前写代码一直在用 Tensorflow,但是 tf 的 API 设计是真的即反人类又反智,要多难用有多难用。针对这个问题,keras 应运而生,API 十分的舒服,省去了很多不必要的代码,谷歌也一是到了这个问题,所以在最新的 tensorflow 中已经提供了 keras 的高阶 API,主要的应用是快速实验模型。
这里我们采用 keras 来实战,有兴趣的可以和 tensorflow 进行对比下。
我们用 imdb 的数据来进行实践,这是一个二分类问题,判断 review 是 positive 还是 negtive 的。输出文本分类或者情感预测的范畴。实验分为三部分:
-
SimpleRNN
-
LSTM
另外,给两个示例代码:
-
Stack of SimpleRNN
-
Dropout for RNN
完整代码参考我的 github: https://github.com/gutouyu/ML_CIA/tree/master/LSTM
看不看不关键,关键是记得 star (手动抱拳)
5.1 SimpleRNN
代码真的超级简单没有没。完整代码参考上面 github。
# 5.1 SimpleRNN
from keras.models import Sequential
from keras.layers import Dense, SimpleRNN, Embedding
from keras import datasets
from keras.preprocessing import sequence
max_features = 10000 # 我们只考虑最常用的10k词汇
maxlen = 500 # 每个评论我们只考虑100个单词
(x_train, y_train), (x_test, y_test) = datasets.imdb.load_data(num_words=max_features)
print(len(x_train), len(x_test))
x_train = sequence.pad_sequences(x_train, maxlen=maxlen)
x_test = sequence.pad_sequences(x_test, maxlen=maxlen) #长了就截断,短了就补0
model = Sequential()
model.add(Embedding(max_features, 32))
model.add(SimpleRNN(32))
model.add(Dense(1, activation='sigmoid'))
model.summary()
model.compile(
optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['acc'])
history = model.fit(
x_train,
y_train,
epochs=10,
batch_size=128,
validation_split=0.2)
plot_acc_and_loss(history)
rets = model.evaluate(x_test, y_test)
print(rets)
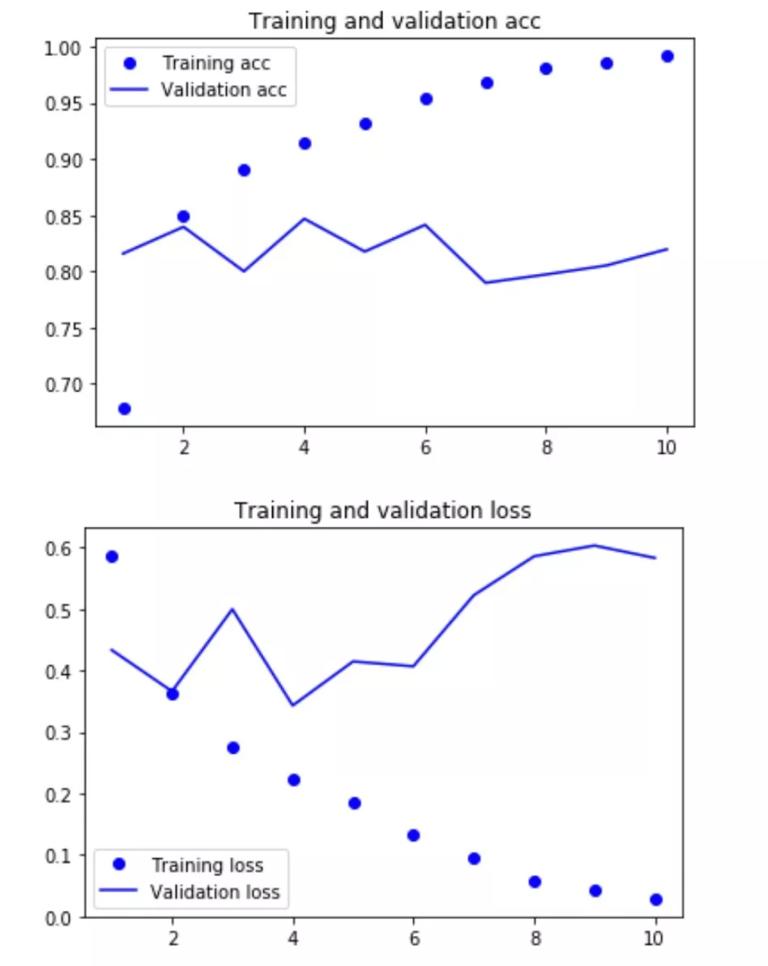
结果截图:
validation 的 acc 大约能到 85% 左右。我们只用了 500 个 word 并没有使用全部的 word,而且 SimpleRNN 并不太适合处理 long sequences。期待 LSTM 能有更好的表现.
5.2 LSTM
只用把模型这一部分换了就行了:
model = Sequential()
model.add(Embedding(max_features, 32))
model.add(LSTM(32))
model.add(Dense(1, activation='sigmoid'))
model.summary()
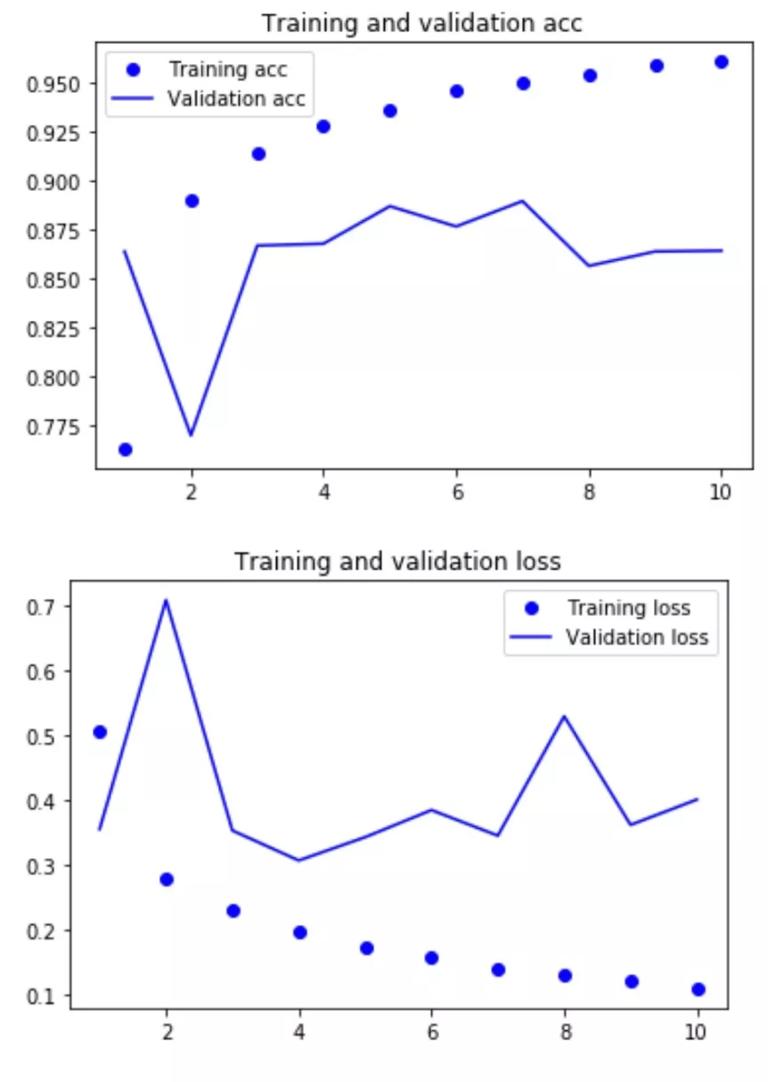
运行结果:
验证集结果在 89%,相比之前的 SimpleRNN 的 85% 提升效果显著
5.3 Stack RNN
上面的模型已经是过拟合了,所以模型的表达能力是够的,这里只是给大家参考下如何 stack RNN
model = Sequential()
model.add(Embedding(max_features, 32))
model.add(SimpleRNN(64, return_sequences=True))
model.add(SimpleRNN(32, return_sequences=True))
model.add(SimpleRNN(16))
model.add(Dense(1, activation='sigmoid'))
5.4 Dropout for RNN
上面的模型已经过拟合了,大家可以参考下面的代码增加 Dropout 来调整;需要注意点的是,dropout 会降低模型的表达能力,所以可以尝试再 stack 几层 rnn。
dropout 同样适用于 lstm layer,留给大家自己去尝试吧。
model = Sequential()
model.add(Embedding(max_features, 32))
model.add(SimpleRNN(64, dropout=0.1, recurrent_constraint=0.5, return_sequences=True))
model.add(SimpleRNN(32, dropout=0.1, recurrent_constraint=0.5))
model.add(Dense(1, activation='sigmoid'))
六、总结
-
LSTM 关键在于增加了 carry track,稍微复杂一点的在于 carry track 上 c_t 信息的更新
-
Recurrent Neural Network 适合 sequence 或 timeseries 问题
-
keras 的 API 非常的人性化,如果是学习或者做实验建议使用 keras,而且 tf 现在也已经内置 keras api 可以通过
from tensorflow import keras来使用 -
keras 内置 SimpleRNN, LSTM, GRU,同时还可以使用 1D-Conv 来处理 sequence 或 timeseries 问题
-
可以给 stack RNN 来增加模型的表达能力
-
可以使用 dropout 来对抗 RNN 的过拟合
Reference
- Deep Learning with python

时间:2019-05-25 00:15 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
- [机器学习]堪比当年的LSTM,Transformer引燃机器学习圈:它是
- [机器学习]人工智能十年回顾:CNN、AlphaGo、GAN……它们曾这
- [机器学习]机器学习基础图表:概念、原理、历史、趋势和算法
- [机器学习]20年以后,半数工作将被人工智能取代?这些“高危行业”有哪些
- [机器学习]堪比当年的LSTM,Transformer引燃机器学习圈:它是
- [机器学习]人工智能十年回顾:CNN、AlphaGo、GAN……它们曾这
- [机器学习]年终总结:2021年五大人工智能(AI)和机器学习(ML)发展趋势
- [机器学习]神经科学如何影响人工智能?看DeepMind在NeurIPS2
- [机器学习]美俄人工智能军事应用
- [机器学习]民调不靠谱?人工智能预测拜登获胜
相关推荐:
网友评论:















