贝壳搜索平台实时流总体架构设计
1. 总体架构
如下图所示,新的实时流重度依赖 kafka,实现了平台各个处理阶段的异步化。
另外,整个服务的构建是基于 springcloud,借助 spring config 实现了业务接入的可配置化。
1.1 事件平台
事件平台作为一个独立的服务存在,对阿里开源的 canal 进行了定制化开发,实现对数据库变更的监听,并把变更格式化后写入 kafka;格式化后的事件示例如下:
1. `{`
2. `"changed":{`
3. `"field1":{`
4. `"after":"aaa",`
5. `"before":"a"`
6. `},`
7. `"field2":{`
8. `"after":"bb",`
9. `"before":"xx"`
10. `}`
11. `},`
12. `"content":{`
13. `"field1":"aa",`
14. `"field2":"bb",`
15. `"field3":"cc"`
16. `},`
17. `"database":"test_db",`
18. `"table":"test_table",`
19. `"timestamp":1521021260000,`
20. `"traceId":6976412492031196000,`
21. `"type":"UPDATE"`
22. `}`
1.2 事件构造 / 接收系统
事件构造 / 接收系统作为一个整体,消费事件平台的格式化数据,从中过滤出自己感兴趣的部分(比如哪个库,哪个表,哪些字段变更),并从事件中取出对应的业务唯一主键,重新写入下游的 kafka 队列中。
1.3 数据构造 / 接收系统
同事件构造 / 接收系统类似,数据构造 / 接收系统也是作为一个整体,作为前者的下游,拿上游 kafka 队列中的业务唯一主键,回调相应业务方,拿到业务方返回的索引数据,写入到下游 kafka。索引数据格式如下:
1. `{`
2. `"data":{`
3. `"fieldx":"123",`
4. `"fieldy":"yy",`
5. `"fieldz":"zz"`
6. `},`
7. `"id":"123",`
8. `"timestamp":1514377005000,`
9. `"action":"UPDATE",`
10. `"version":"v1.0",`
11. `"traceId": 6976412492031196000`
12. `}`
字段及释义
| 字段 | 释义 |
|---|---|
| id | 业务相关唯一标识符,如房源 id,一般情况下对应 data 中某字段,不强制限制 |
| timestamp | 事件产生的时间 |
| traceId | 全链路追踪使用 |
| action | 事件类型,可用的类型为更新 / 删除 / 部分更新 |
| version | 数据版本,扩展使用 |
| data | 对应 es 索引中的数据 |
1.4 索引服务
作为数据构造 / 接收系统的下游服务,索引服务将构建好的数据直接写入到 es 中。除此之外,索引服务还承担了索引的管理工作,比如:索引初始化,索引结构调整,索引别名切换,索引数据恢复等等
- 可以看到,借助 kafka,整个架构内各个上下游服务之间实现了解耦,并且以上服务可以集群的方式自由部署及扩展
1.5 PULL + PUSH
为了便于灵活的接入,平台设计之初就确定了两种模式:PULL 和 PUSH。主要有以下三种场景:
1)无实时更新:可以直接采用 PUSH 的方式,把拼好的数据通过数据接收系统直接写入。
2)实时更新 +“1 对 1”:如房源,一个房源价格的变更,只会影响当前这个房源;这种场景,可以由平台来负责监听变更,最后 PULL 业务接口来实现数据的同步。
3)实时更新 +“1 对多”:还拿房源举例子,房源对应小区名变更,会影响到小区内所有房源;这种场景,业务方可以自己监听变更,然后把变更 PUSH 给数据接收系统。
另外,对应 2),业务方可以提供全量接口,事件构造系统拉取所有数据,然后包装成全量事件(实时增量为增量事件),对整个索引数据进行更新(索引概念后面介绍)
2. 问题及方案
2.1 并发 vs 数据一致性
为了提高数据同步的速度(主要针对全量更新或者刷数据的情况),整个实时流架构下各个服务都支持并发处理,这个功能由 kafka topic 的多 partition 来支持 (partition 概念可以参考http://kafka.apache.org/documentation/#intro_topics)。
如上图所示,topic 配置有 0,1,2 三个 partition,对于同一个业务单元(如房源 123456)的多次变更,默认情况下会被写入到任何一个 partition,这时,由于消费进度不一致,后变更可能会被先处理,这样就有数据不一致的风险。问题就来了,我们如何能保证同一个业务单元的变更能写入到同一个 partiton 呢?
Kafka 生产者 client 文档中的描述如下:
If a valid partition number is specified that partition will be used when sending the record. If no partition is specified but a key is present a partition will be chosen using a hash of the key. If neither key nor partition is present a partition will be assigned in a round-robin fashion.
由于 partition 数本身是不可控的,所以直接指定 partition 写入是不可取的,而轮询的方式(round-robin)明显是有问题的,最终我们采用指定 key 的方式;在生产者写入数据到 kafka 时,以业务单元的唯一标识(如房源 Id)做为 key;这样我们就可以保证对应同一个业务单元,不管有多少次变更,相关信息都会写入到同一个 partition 中(也就是同一个队列中),从而在并发的同时保证数据的一致性
2.2 异步化 vs 全链路追踪
考虑到整个架构是基于 springcloud,最初选用的了 springcloud 生态下的 sleuth(对 zipkin 进行了封装) 以实现全链路追踪,方便排查问题,分析处理过程中耗时情况。zipkin 官网效果图如下。
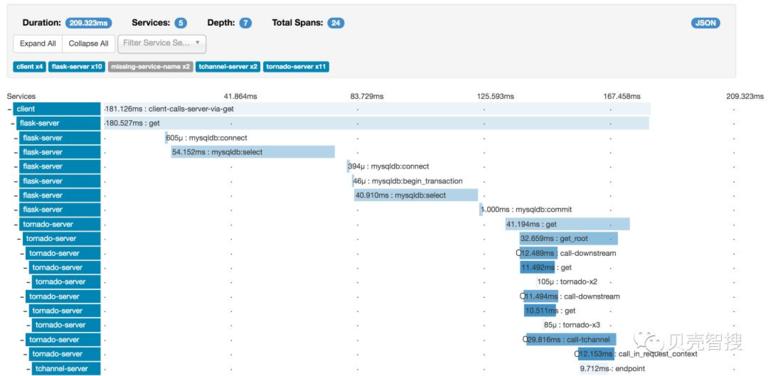
由上图可以很直观看到,所示的链路信息是同步请求的,也就是在结果返回前请求端会一直阻塞。由前文描述,我们可以知道,我们采用使用 kafka 使系统各个部署实现了异步化,这样就给全链路追踪带来的问题。虽然 zipkin 本身已经对 kafka 的传输有了支持(参考:Existing instrumentations),但是由于 kafka 消息的读 / 写都是批量的,并不能支持单条数据粒度的链路追踪(参考:Brave Kafka instrumentation)
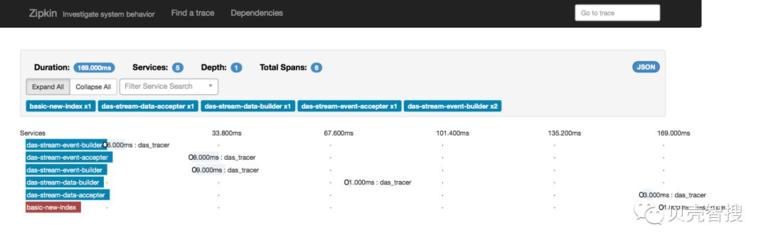
通过对 sleuth java 客户端的源码进行分析发现,全链路追踪的数据是由 traceId 来串起来的,默认情况下,traceId 是自动生成的。基于源码的分析,我们对 zipkin 客户端数据收集模块进行了重写,由业务代码来控制 traceId 的生成,并且,把 traceId 做为业务数据的一部分,在整个处理流程中一直传下去;显式控制追踪数据的上传,从而可灵活指定埋点,以及具体的埋点信息。
整体效果可见下图。
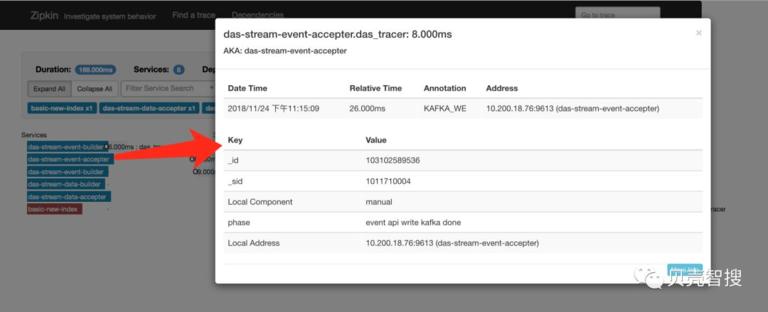
自定义埋点信息效果见下图。其中 _sid 和 _id 对应于具体的业务方以及具体的数据,可以做为 zipkin 页面上的检索条件。
2.3 可扩展 vs 业务隔离
原则上,在以上描述的架构中,我们是可以接入的业务数目是没有限制的,各个结点都是可以根据需求来扩展的。但是,在具体的使用中,我们还是遇到了一些问题,某个业务出现异常,导致整个系统不可用的情况。
2.3.1 硬件资源共享的风险
在我们的一次事故中,事件构造系统出现过硬件资源共享引发的问题。由 1.2 可知,事件构造系统是主要功能是消费事件平台的 kafka 消息,从中提取感兴趣的数据,为了排查问题以及对消费延时感知,我们会把消费到的数据打印日志持久化到磁盘中,并且在延时(由消息生成时间对比系统当前时间)时发出报警。某天,由于某业务异常操作(后续排查到是大批量刷数据),导致单位时间内日志打印过多,磁盘空间占满,并且报警队列过大,内存溢出,最终导致整个服务 block,影响到了所有业务。
2.3.2 线程共享的风险
在事件 / 数据接收系统中,kafka 消息写入时,是共用同一个 producer 的,producer 本身是线程安全,官方文档也是推荐多线程共享使用的。但是,在我们的实际使用中,发现了这样的问题:新上线业务,由于 kafka topic 漏申请,导致整个服务 block。后续分析具体原因发现,同一个 producer,其中有个缓冲区是共享的,某个 topic 不存在,对应的数据就会在缓冲区中堆积,直到堆积满,从而影响到我其它业务的正常使用。
以上问题,我们通过系统升级和流程规范都已经解决,但是其中也暴露的问题值得我们深思。作为一个平台提供方,所接入业务的重要程度、更新的量级、对数据实时性的要求都是不一样的。如果硬件资源(如网络 IO、内存、磁盘都共享)和线程资源共享,那么业务之间是存在相互影响的,并且这个风险基本上是不可控的。
由此,在我们已经规划(也是在实施中)的服务部署方案中,机房、业务类型、重要程度、业务量级都是考虑因素,我们以此对服务进行分组部署,避免相互干扰
2.4 全量 + 增量 vs 数据一致性
2.4.1 基本概念和问题
概念定义
全量:对应某个业务在某个时间点的所有有效数据
增量:某个业务实时更新的数据
索引:对应 es 中的一个索引,具体概念类似数据库的一张表
别名:对应 es 中的别名,可以指向一个索引,在别名和索引一对一的情况下,访问别名等同访问索引;es 本身支持别名和索引多对多;平台的设计是通过别名来读取 es 数据的;
消费者分组:kafka 中的 consumer group 概念,对于同一个 topic,多个消费者分组可以消费完整的数据,彼此相互不影响
数据一致性:数据的最终一致性,对于某个业务方,在可以容忍的时间内,搜索索引中的数据量与业务方的数据量一致,所有数据的值与业务方数据保持一致。
在存在实时增量的场景下,一般都会存在以下问题:
1)全量和增量同时进行时,如何保证数据的先后顺序?
2)全量数据如何不影响正常增量的实时性?
3)全量结束后如何删除旧数据?
4)全量 / 增量如何保证数据不丢失?
以上问题,在存在实时增量的场景都是不可回避的话题,贝壳搜索平台在迭代过程解决这几个问题主要采用了两种方式:1)单索引 + 多消费者分组;2)多索引别名关联方案
2.4.2 全量方式
2.4.1 方案 1:单索引 + 多消费者分组
该方案下,无全量时,只存在一个 es 索引,做全量时会新建一个索引;在做全量过程,旧的索引只写入增量,新的索引会写入增量和全量数据;全量结束时,别名指向新的索引。示意图如下,需要注意的是,每次全量索引 B 不是同一个索引。
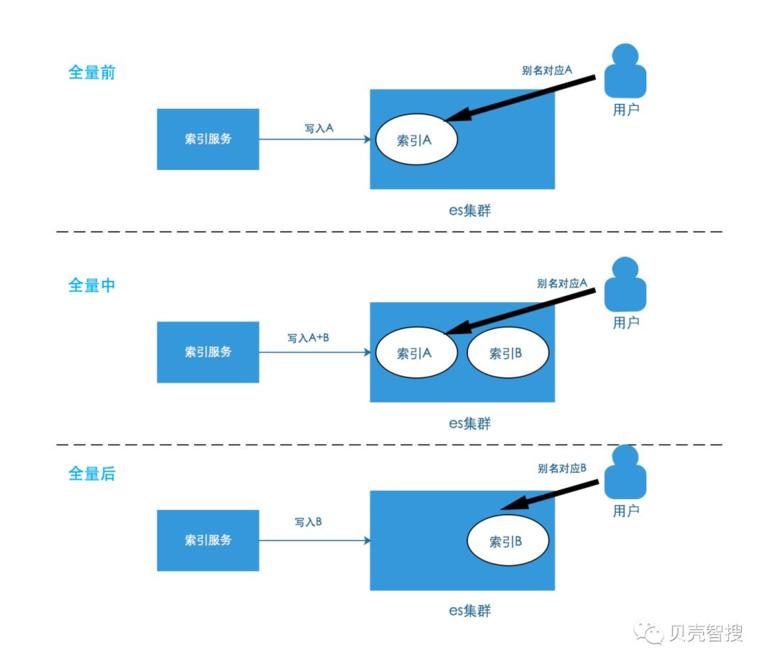
1)数据先后顺序
两种方案解决方式是一致的,可以参考 2.1 的描述。以同一个房源为例,变更事件本身是不区分顺序的,最终写到索引的数据都是来自于数据构造系统。对于同一个索引,同一个房源变更都只会被同一个数据构造系统收到,然后通过数据接收系统写入到同一个 topic-partition 中,最终数据也只会被同一个索引服务写入到 es。所以在整个处理链条中,同一个房源的变更是可以保持顺序的。
2)全量不影响增量
这里用到了前面提到的 kafka 的消费者分组概念。
首先,我们对事件和数据增加了标识,分为全量(DUMP)和增量(UPDATE)。当触发全量时,索引服务会自动按时间戳生成一个新的索引,然后把所有 DUMP 和 UPDATE 数据都会往新的索引中写入,而旧的索引中只写入 UPDATE 数据。同时,全量过程中,事件 / 数据构造系统会自动创建新的线程来使用不同的消费分组来分别处理 DUMP 和 UPDATE 数据。由于增量线程会把 DUMP 数据直接丢掉,而只处理 UPDATE 数据,所以,全量基本不会影响到增量的实时性。
3)全量结束后旧数据删除
由于是新建索引,所以不存在旧数据的问题
4)全量 / 增量不丢失
首先,对于同一个业务方的数据,在平台内系统间流传是依赖 kafka 数据传输 AT-LEAST-ONCE 语义保证的,不会丢失。另外,回调业务方接口返回失败,会在异步队列中无限次重试,同时发出报警。
2.4.2 方案 2:多索引别名关联方案
同方案 1 最大的区别在于,方案 2 使用了多个索引,比如有两个索引 A 和 B。A 和 B 通过别名 N 来关联起来,同一个时刻,N 只会对应 A 和 B 中的一个。写入数据时,会向 A 和 B 两个索引同时写入,读数据时通过别名 N 来读取。做全量时触发 A 或者 B,比如我们触发 A,这时会把全量数据以及实时增量都写入到 A 索引中,全量完成后,让别名 N 指向 A,这样,用户就可以从 A 中读取数据了。示意图如下。
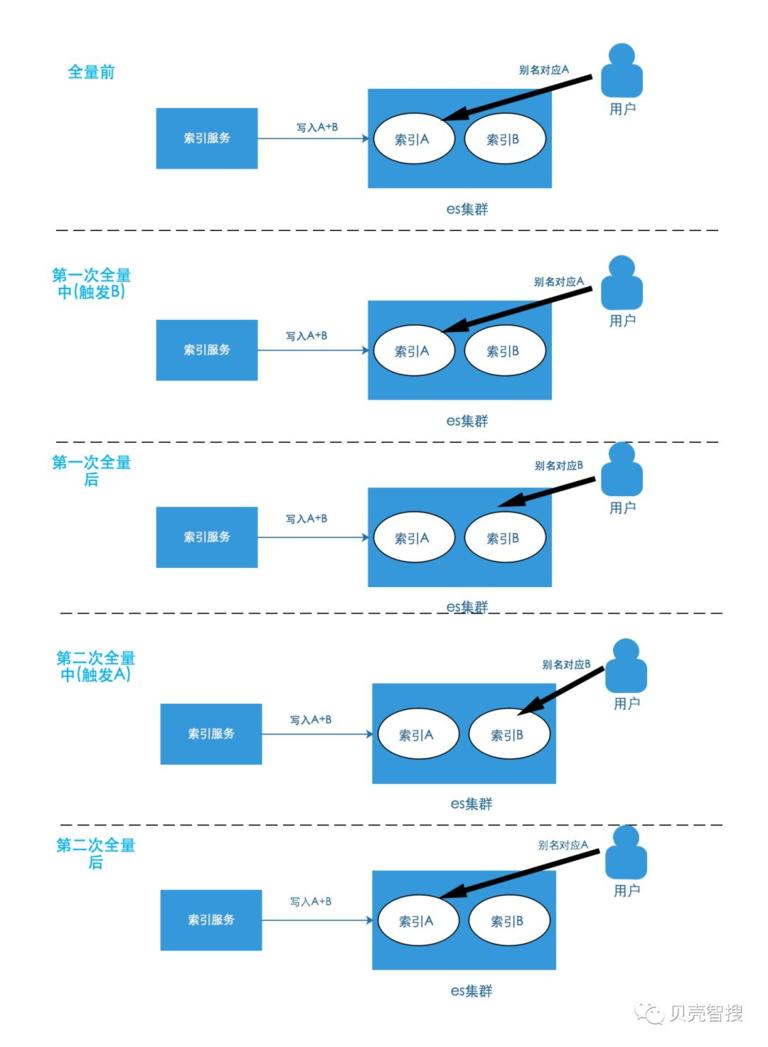
1)数据先后顺序
同方案 1
2)全量不影响增量
很明显,当触发 A 来做全量时,N 指向 B,那么全量是不影响增量的实时性的。
3)全量结束后旧数据删除
可以支持多种删除策略,如按时间戳删除(索引中每条数都加上更新时间,删除结束时,删除全量开始那个时间点之前的数据)、不删除、按具体业务条件删除(如删除 type=1 的数据)
4)全量 / 增量不丢失
同方案 1
小结
–
本文第一部分简单介绍了贝壳搜索平台的整体架构,并简单描述了各个模块系统的职责及实现思路;在第二个部分中,比较详细地描述了,如何并发同时保证数据一致性、异步化下的全链路追踪方案、可扩展与隔离的权衡以及两个全量方案。希望能通过此文给读者些许启发和参考,感谢阅读!

时间:2019-03-12 23:10 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
相关推荐:
网友评论:















