在Python中处理JSON数据
我最近完成了两项工作——基于spark的数据摄取框架和基于spark的数据质量框架;都是元数据驱动的。通常,都是存储在RDBMS中。在数据摄取框架中,我需要存储源(用户名、密码、路径、格式等信息)、目标(用户名、密码、路径、格式等信息)、压缩等参数。在普通模式中,我看到这些参数被建模为表中的列。

by Bipin Patwardhan 来源:DZone
作为一名程序员,我决定不使用multiple columns。相反,所有参数将存储在单个column中(作为数据库表中的字符串)。Spark应用程序将负责读取字符串并提取所需的参数。
做出这个(看起来很简单的)决定之后,下一步是定义“参数”字符串的格式。为此,我毫不犹豫地选择了JSON。虽然解析类似于csv的格式很容易,但是JSON提供了很多灵活性——但是要付出一些代价。
在Spark中研究JSON解析的各种选项之后,我使用Scala解析库,开发了一个Scala类来实现这个目的,在编程世界中,完成一项任务的方法不止一种,即使是对于JSON解析,也有许多可用的库,如Json4s、Play JSON、Spray JSON等。
在使用Scala解析JSON之后,我想在Python中尝试一些类似的东西。我发现在Python中JSON解析很简单(本质上就是一个导入和一行代码)。

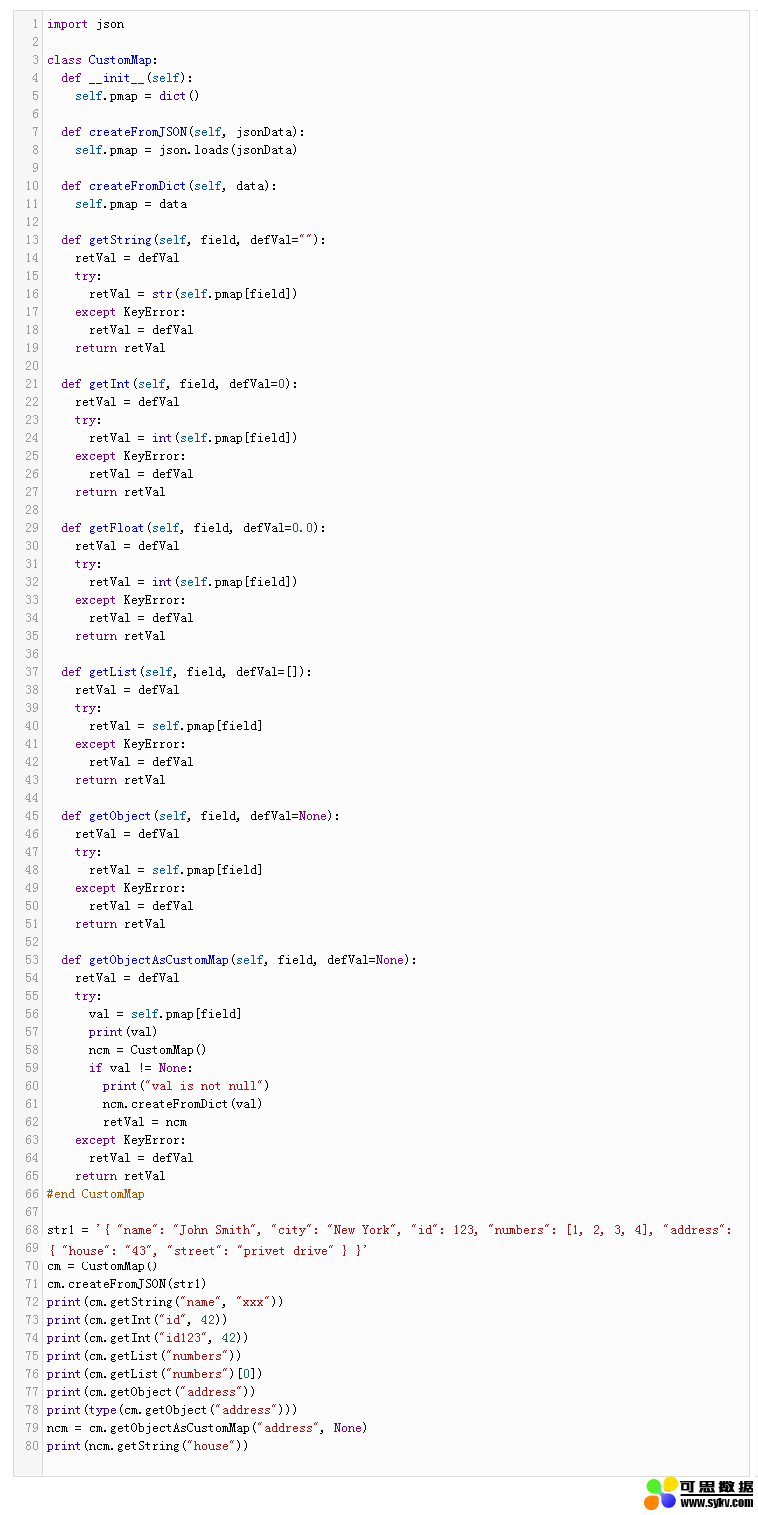
由于我们习惯于将简单的事情复杂化,所以我决定将JSON解析逻辑封装在一个名为CustomJSON的类中。

时间:2019-10-16 22:32 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
- [数据挖掘]底层I/O性能大PK:Python/Java被碾压,Rust有望取代
- [数据挖掘]RedMonk语言排行:Python力压Java,Ruby持续下滑
- [数据挖掘]不得了!Python 又爆出重大 Bug~
- [数据挖掘]TIOBE 1 月榜单:Python年度语言四连冠,C 语言再次
- [数据挖掘]TIOBE12月榜单:Java重回第二,Python有望四连冠年度
- [数据挖掘]这个可能打败Python的编程语言,正在征服科学界
- [数据挖掘]2021年编程语言趋势预测:Python和JavaScript仍火热,
- [数据挖掘]Spark 3.0重磅发布!开发近两年,流、Python、SQL重
- [数据挖掘]Python 为什么推荐蛇形命名法?
- [数据挖掘]Python才是世界上最好的语言
相关推荐:
网友评论:















