将sklearn训练速度提升100多倍,美国「返利网」开源sk-dist框架
在本文中,Ibotta(美国版「返利网」)机器学习和数据科学经理 Evan Harris 介绍了他们的开源项目 sk-dist。这是一个分配 scikit-learn 元估计器的 Spark 通用框架,它结合了 Spark 和 scikit-learn 中的元素,可以将 sklearn 的训练速度提升 100 多倍。
在 Ibotta,我们训练了许多机器学习模型。这些模型为我们的推荐系统、搜索引擎、定价优化引擎、数据质量等提供了支持,在与我们的移动 app 互动的同时为数百万用户做出预测。
虽然我们使用 Spark 进行大量的数据处理,但我们首选的机器学习框架是 scikit-learn。随着计算成本越来越低以及机器学习解决方案的上市时间越来越重要,我们已经踏出了加速模型训练的一步。其中一个解决方案是将 Spark 和 scikit-learn 中的元素组合,变成我们自己的融合解决方案。
项目地址:https://github.com/Ibotta/sk-dist
何为 sk-dist
我们很高兴推出我们的开源项目 sk-dist。该项目的目标是提供一个分配 scikit-learn 元估计器的 Spark 通用框架。元估计器的应用包括决策树集合(随机森林和 extra randomized trees)、超参数调优(网格搜索和随机搜索)和多类技术(一对多和一对一)。

我们的主要目的是填补传统机器学习模型分布选择空间的空白。在神经网络和深度学习的空间之外,我们发现训练模型的大部分计算时间并未花在单个数据集上的单个模型训练上,而是花在用网格搜索或集成等元估计器在数据集的多次迭代中训练模型的多次迭代上。
实例
以手写数字数据集为例。我们编码了手写数字的图像以便于分类。我们可以利用一台机器在有 1797 条记录的数据集上快速训练一个支持向量机,只需不到一秒。但是,超参数调优需要在训练数据的不同子集上进行大量训练。
如下图所示,我们已经构建了一个参数网格,总共需要 1050 个训练项。在一个拥有 100 多个核心的 Spark 集群上使用 sk-dist 仅需 3.4 秒。这项工作的总任务时间是 7.2 分钟,这意味着在一台没有并行化的机器上训练需要这么长的时间。
- import timefrom sklearn import datasets, svm
- from skdist.distribute.search import DistGridSearchCV
- from pyspark.sql import SparkSession # instantiate spark session
- spark = (
- SparkSession
- .builder
- .getOrCreate()
- )
- sc = spark.sparkContext
- # the digits dataset
- digits = datasets.load_digits()
- X = digits["data"]
- y = digits["target"]
- # create a classifier: a support vector classifier
- classifier = svm.SVC()
- param_grid = {
- "C": [0.01, 0.01, 0.1, 1.0, 10.0, 20.0, 50.0],
- "gamma": ["scale", "auto", 0.001, 0.01, 0.1],
- "kernel": ["rbf", "poly", "sigmoid"]
- }
- scoring = "f1_weighted"
- cv = 10
- # hyperparameter optimization
- start = time.time()
- model = DistGridSearchCV(
- classifier, param_grid,
- sc=sc, cv=cv, scoring=scoring,
- verbose=True
- )
- model.fit(X,y)
- print("Train time: {0}".format(time.time() - start))
- print("Best score: {0}".format(model.best_score_))
- ------------------------------
- Spark context found; running with spark
- Fitting 10 folds for each of 105 candidates, totalling 1050 fits
- Train time: 3.380601406097412
- Best score: 0.981450024203508
该示例说明了一个常见情况,其中将数据拟合到内存中并训练单个分类器并不重要,但超参数调整所需的拟合数量很快就会增加。以下是运行网格搜索问题的内在机制,如上例中的 sk-dist:
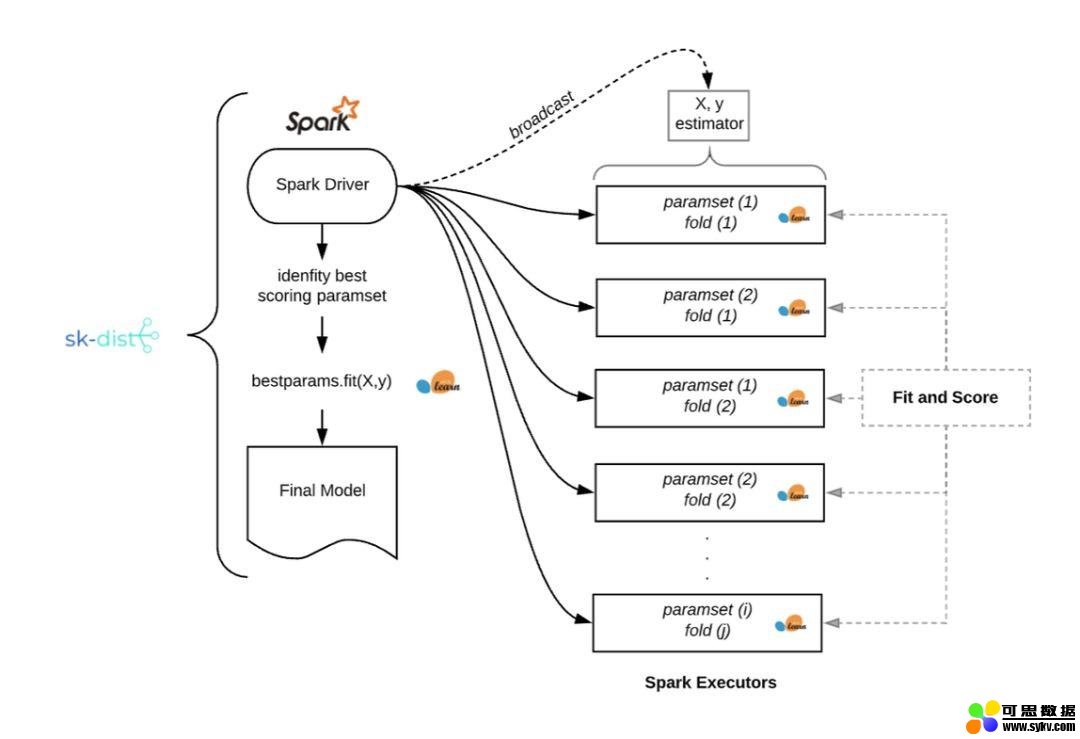
使用 sk-dist 进行网格搜索
对于 Ibotta 传统机器学习的实际应用,我们经常发现自己处于类似情况:中小型数据(100k 到 1M 记录),其中包括多次迭代的简单分类器,适合于超参数调优、集合和多类解决方案。
现有解决方案
对于传统机器学习元估计训练,现有解决方案是分布式的。第一个是最简单的:scikit-learn 使用 joblib 内置元估计器的并行化。这与 sk-dist 非常相似,除了一个主要限制因素:性能受限。即使对于具有数百个内核的理论单台机器,Spark 仍然具有如执行器的内存调优规范、容错等优点,以及成本控制选项,例如为工作节点使用 Spot 实例。
另一个现有的解决方案是 Spark ML。这是 Spark 的本机机器学习库,支持许多与 scikit-learn 相同的算法,用于分类和回归问题。它还具有树集合和网格搜索等元估计器,以及对多类问题的支持。虽然这听起来可能是分配 scikit-learn 模式机器学习工作负载的优秀解决方案,但它的分布式训练并不能解决我们感兴趣的并行性问题。
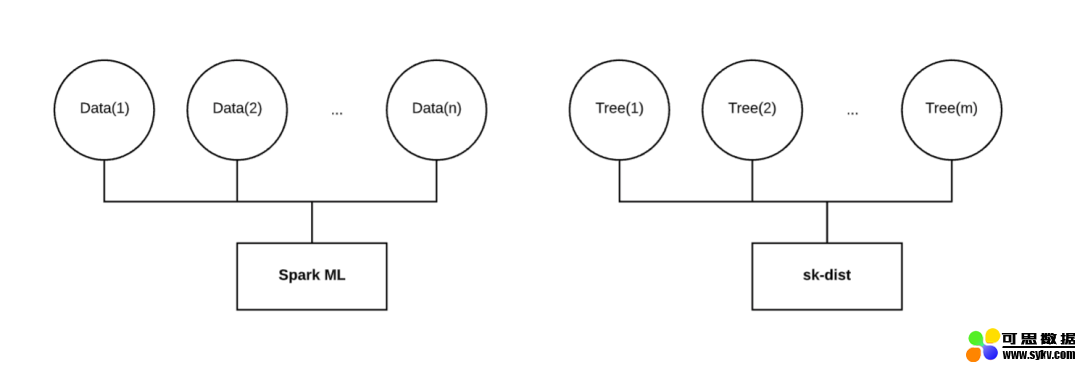
分布在不同维度
如上所示,Spark ML 将针对分布在多个执行器上的数据训练单个模型。当数据很大且无法将内存放在一台机器上时,这种方法非常有效。但是,当数据很小时,它在单台计算机上的表现可能还不如 scikit-learn。此外,当训练随机森林时,Spark ML 按顺序训练每个决策树。无论分配给任务的资源如何,此任务的挂起时间都将与决策树的数量成线性比例。
对于网格搜索,Spark ML 确实实现了并行性参数,将并行训练单个模型。但是,每个单独的模型仍在对分布在执行器中的数据进行训练。如果按照模型的维度而非数据进行分布,那么任务的总并行度可能是它的一小部分。
最终,我们希望将我们的训练分布在与 Spark ML 不同的维度上。使用小型或中型数据时,将数据拟合到内存中不是问题。对于随机森林的例子,我们希望将训练数据完整地广播给每个执行器,在每个执行器上拟合一个独立的决策树,并将那些拟合的决策树返回驱动程序以构建随机森林。沿着这个维度分布比串行分布数据和训练决策树快几个数量级。这种行为与网格搜索和多类等其他元估计器技术类似。
特征
鉴于这些现有解决方案在我们的问题空间中的局限性,我们决定在内部开发 sk-dist。最重要的是我们要「分配模型,而非数据」。
sk-dist 的重点是关注元估计器的分布式训练,还包括使用 Spark 进行 scikit-learn 模型分布式预测的模块、用于无 Spark 的几个预处理/后处理的 scikit-learn 转换器以及用于有/无 Spark 的灵活特征编码器。
分布式训练:使用 Spark 分配元估计器训练。支持以下算法:超参数调优(网格搜索和随机搜索)、决策树集合(随机森林、额外随机树和随机树嵌入)以及多类技术(一对多和一对一)。
分布式预测:使用 Spark DataFrames 分布拟合 scikit-learn 估算器的预测方法。可以通过便携式 scikit-learn 估计器实现大规模分布式预测,这些估计器可以使用或不使用 Spark。
特征编码:使用名为 Encoderizer 的灵活特征转换器分布特征编码。它可以使用或不使用 Spark 并行化。它将推断数据类型和形状,自动应用默认的特征转换器作为标准特征编码技术的最佳预测实现。它还可以作为完全可定制的特征联合编码器使用,同时具有与 Spark 分布式转换器配合的附加优势。
用例
以下是判断 sk-dist 是否适合你的机器学习问题空间的一些指导原则:
传统机器学习 :广义线性模型、随机梯度下降、最近邻算法、决策树和朴素贝叶斯适用于 sk-dist。这些都可在 scikit-learn 中实现,可以使用 sk-dist 元估计器直接实现。
中小型数据 :大数据不适用于 sk-dist。请记住,训练分布的维度是沿着模型变化,而不是数据。数据不仅需要适合每个执行器的内存,还要小到可以广播。根据 Spark 配置,最大广播大小可能会受到限制。
Spark 定位与访问:sk-dist 的核心功能需要运行 Spark。对于个人或小型数据科学团队而言,这并不总是可行的。此外,为了利用 sk-dist 获得最大成本效益,需要进行一些 Spark 调整和配置,这需要对 Spark 基础知识进行一些训练。
这里一个重要的注意事项是,虽然神经网络和深度学习在技术上可以与 sk-dist 一起使用,但这些技术需要大量的训练数据,有时需要专门的基础设施才能有效。深度学习不是 sk-dist 的预期用例,因为它违反了上面的 (1) 和 (2)。在 Ibotta,我们一直在使用 Amazon SageMaker 这些技术,我们发现这些技术对这些工作负载的计算比使用 Spark 更有效。

时间:2019-09-30 07:33 来源:可思数据 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
相关推荐:
网友评论:















