我们是如何删除 PB 级重复数据的?
Mixpanel 通过网络从移动端、浏览器端和服务器端的客户接入了千万亿字节的事件数据。由于网络的不可靠性,客户可能会不断重复发送事件请求,直到他们收到来自 Mixpanel 的 200 OK(连接成功)消息。虽然这种重试策略避免了数据丢失,但是在系统中创建了大量的重复事件。对这类重复事件的数据的分析也非常容易产生问题,因为它对所发生的事给出了一个不准确的描述,这也会导致 Mixpanel 偏离其它正在同步的客户端数据系统,如数据仓库。这也是为什么我们非常关心数据完整性的原因。
今天,我们很高兴在这里分享我们的 PB 级规模的事件数据去重解决方案。
要求
为解决这个问题,我们需要一个能够满足以下要求的方案:
可扩展性:能够扩展到百万事件 / 秒的接入量
低成本:为接入、存储和查询优化成本 / 性能负载
可追溯性:能够对任意发送的事件进行重复识别
可恢复性:保留重复数据从而在配置错误时可以回滚
可维护性:最小化运营负载
最新技术:接入 - 时间去重
业界有很多富有创造性的方法来解决数据去重问题。其核心策略是在接入层构建一个能够去重的的基础设施。客户发送的每个事件都有一个唯一的 insertid属性标识。数据去重基础设施会将所有事件的insertid属性标识。数据去重基础设施会将所有事件的insert_id 保存一定期限(例如 7 天),期间将会与每个新事件进行匹对,以查找去重标识。键值通常是用存储的分片的 RocksDB 或 Cassandra。通过使用布隆过滤器来优化存储中的查找成本。这种架构能够确保在系统入口点就将重复内容清除。
但是,这种方法并不符合我们的要求,原因如下:
√ 扩展性:分片键值存储可以水平扩展
× 低成本:需要一个单独的数据库和基础设施来保存重复数据
× 可追溯性:只能抓取一定时间段的重复数据
× 可恢复性:抓取时丢弃数据,不能回滚
× 可维护性:删除重复数据成为一个额外的服务,必须 24x7 不间断
我们的方案
我们的方案是接入所有事件并在读取时去重,该方案也满足了前面所有的要求。每次查询时,通过构建一个包含所有 $insert_id 的哈希表可以很容易地在读取时实现去重;但是,这会给我们的系统增加一些额外的开销。在详细介绍这个方案之前,让我们先回顾一下 Mixpanel 架构的几个关键技术。
Mixpanel 架构
基于项目、用户和时间的分片
Mixpanel 的分析数据库 Arb 按照项目、用户和时间对数据文件进行了分片。这可以确保指定用户的所有数据都可以共同保存在一个位置,查询时也可以在相关的时间段同时覆盖多个用户。
Lambda 架构
在 Arb 中,所有事件都被写入 AOF(只允许追加的文件),这些文件被周期性地索引(压缩)到后台的柱状文件中。AOF 在达到某个大小或时间阈值时,就会被索引。Arb 通过扫描小型的、实时的 AOF 和大型的、历史的、索引的文件,从而确保查询的实时性和高效性。
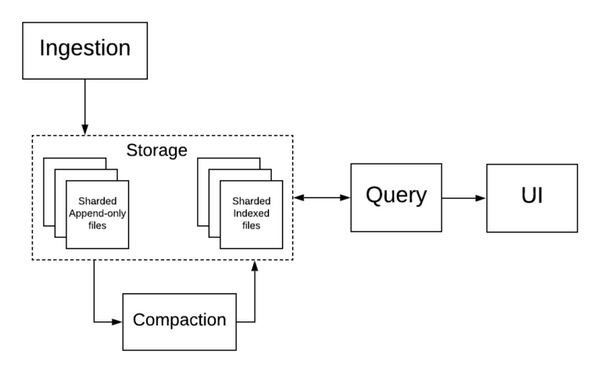
Mixpanel 架构
我们主要利用架构中的这两类文件来提高读时去重的效率。根据第一准则,重复事件具有以下属性:
重复事件属于同一项目
重复事件项属于同一用户
重复事件属于同一事件时间
根据这些属性特征,我们可以:
在搜索空间中搜索项目、用户和日期的重复事件,即搜索单个 Arb 碎片。
通过与 lambda 架构一起摊销来最小化去重开销,从而维护查询的实时和高效。
这帮助我们实现了一个满足所有要求的解决方案。
数据去重架构
在 Mixpanel 的基础设施中,在索引和查询时都可以去重。
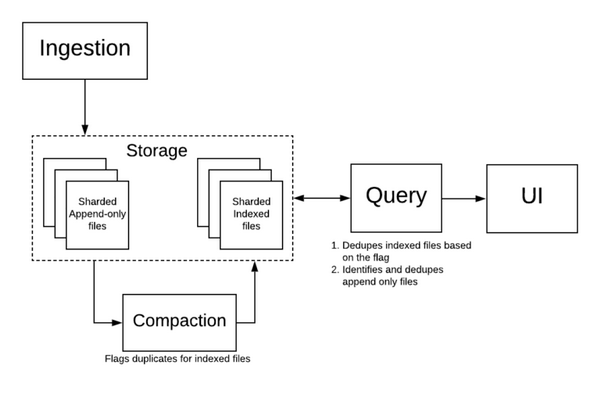
Mixpanel 架构
我们的索引器在内存中维护了一个 hashset,该 hashset 通过 $insert_id 保存了被索引文件中的所有事件。如果某个事件命中,则对该事件设置一个索引格式的重复标记位。这个过程的开销很小,毕竟索引是在细粒度分片级别进行的。
查询时,由于使用了 lambda 架构,我们可以同时扫描索引文件和 AOF。对于索引文件,我们可以检查是否设置了重复位,如果设置了,则跳过处理事件。对于那些小的 AOF,查询可以对 $insert_id 基于散列去重。这可以让我们既实时又高效,充分发挥了 lambda 架构的优势。
性能
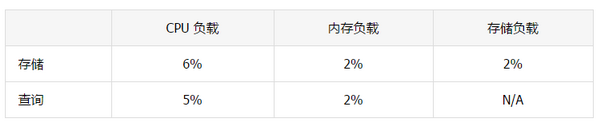
我们从实验中发现,当索引含有 2% 重复的文件时会增加 4% 到 10% 的时间开销。但这并没有对用户体验产生直接影响,因为索引是一个离线过程。
对于查询时间,我们发现当额外读取一个事件的标志位时会增加大约 10ns 的时间。由于增加了额外的列,这使查询时间增加了近 2%。每读取 1000 万个事件会增加约 0.1 秒(100 毫秒)的时间开销。作为参考,由于采取了基于项目、用户和时间的分片,Mixpanel 目前最大的柱状文件包含大约 200 万个事件。我们认为在时间成本上的损失是完全可以接受的,因为我们在数据的保留期限和运营成本上都获得了更大的回报。
未来工作
我们的解决方案并不完美,还有以下场景有待改善:事件可能因为分别保存在 AOF 和索引文件而造成重复。我们可以分别在索引文件或 AOF 中识别出重复项,但不能识别出不同文件中的重复。我们之所以选择忽略这种情况,主要原因如下:
这种情况极其罕见:99.9% 的客户的数据都非常小,以至于一整天的接入量都可以放入一个 AOF 文件中。这意味着 99.9% 的客户不会受到这个问题的影响。
对于可能遇到此问题的大数据客户,我们估计一个事件及其重复数据分别保存到两个文件的几率为 0.5%。
我们的系统会在当日结算时自我修复,当天所有的数据都会重新索引到一个文件中。所以重复数据只会在这一天中短暂出现。
我们发现,这种方法的优势大大超过了其弊端。未来,我们会实现不同文件间的实时去重以及最近几天文件的数据去重。
结语
在文中,我们讨论了在索引层分发重复标识和在查询层分发重复过滤的架构。这个方案已经在 Mixpanel 内部成功运行了 6 个月的时间。
原文链接:https://engineering.mixpanel.com/2019/07/18/petabyte-scale-data-deduplication/

时间:2019-08-01 22:34 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
相关推荐:
网友评论:















