解析业务数据的特征——《企业大数据实践路线
我们今天的内容是解析业务数据的特征。我们已经知道了数据从哪里来,也知道有什么数据,现在我们需要去分析一下这些数据的特征是什么,想想能在这些数据上做什么文章。
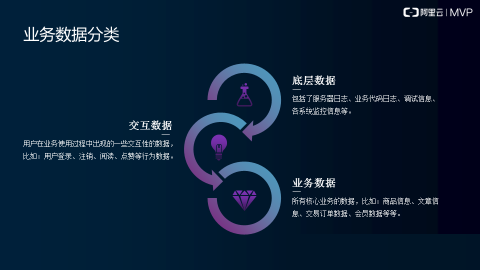
业务数据的分类
首先我们可以了解一下业务数据的分类,其实我们在之前已经说过了,一个是交互数据,一个是底层数据,还有一个是业务数据。交互数据主要是我们在业务使用过程中出现了一些交互性的数据,比如说用户的登录、注销、阅读、点赞这些行为数据。那么底层数据指的是什么呢?主要是我们服务器的日志、业务代码的日志、调试信息等等,这些信息是底层数据,还包括更硬核一点的就是我们系统的监控信息,CPU的占用率,内存的占用率,磁盘IO的变化,网络流量的变化等等。还有一块就是我们业务数据,业务数据主要是我们核心数据,比如说像商品信息、文章信息、交易订单数据、会员数据等等。
我们要去分析三类数据有什么样的特征。一个就是底层数据大部分是日志数据,不能讲100%吧,讲95%以上的底层数据都是日志,或者是以日志形式表达的这样一些数据。所以我们在利用底层数据的时候会有大量精力需要用在梳理出格式和对应的字段内容,更集中化收集下。这是我们在底层数据处理遇到的最大问题。一是你以什么样的合理方式把这些底层数据搜集上来,二是说梳理上来的数据需要进行数据清洗。

在交互数据上我们会遇到几个问题,第一个就是日志类型和数据库内容混杂,结构和非结构数据混杂。而且交互数据还会产生一个问题,它涉及到的关联数据非常多,比如说你的一段交互内容可能会有一行日志,但是这个日志背后有一篇文章,可能有一个用户,甚至有一条评论,可能还有一些其他更深层次的一些关联信息,这些信息的关联就是很麻烦,因为相对于说在底层数据的处理上,只需要把日志拆开,一个字段一个字段去了解它的含义。交互数据拆开之后还要思索它的关联,然后还会产生不同业务系统的关联,这是交互数据带来的问题。
业务数据这一块,通常是跟用户有非常深度的关联关系,而且对安全性的要求非常高。这就给很多企业数据上云带来一些问题,企业甚至会选择一个混合云的架构或者是私有云的架构,然后所有的操作全在自己的私有云上去完成,这是它的物理特性。那么它的逻辑特性是什么呢?这些业务数据的关联,深度很深,举个例子,一个用户的消费记录可能只有一行信息,但是这个消费记录代表的含义可能会涉及到商品信息,商品信息后面还会关联到这个商品当时的营销计划,还会关联这个用户账户的现金变动或者是交互余额的变动,关联发货的清单或者是物流信息流转等等。仅仅只是一个消费记录单能关联出来或者是带出来的数据维度非常之多,所以这是业务数据一个表现特性。相对于交互数据的关联来说,它是层次更深一点,交互数据它关联的主要是横向,扁平化的,就是不会有太深层次的关联,而业务数据会往下探,下钻,然后产生更多维度的深层次关联。这是我们业务数据的特征。
常见的Web应用工作流分析
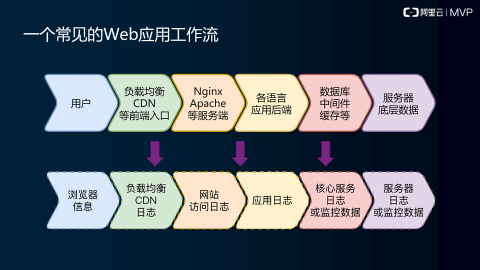
我们可以通过一个具体的例子来解析一下,一个常见的WEB应用的工作流。用户的流量过来,然后到负载均衡或者是CDN或者是服务器前端入口HTTP或者是HTTPS一个入口。然后这些入口把流量分发给到WEB服务器,Nginx或者是别的一些服务端。然后服务端后再对各个语言的应用进行工作,把响应传回去,在这个工作过程中我们还会涉及到数据库、中间件、缓存,这些操作又会关联服务器底层数据,这是整个深层次的过程。
我们可以通过这样的方式去拆解每个环节对应的数据。用户环节我们能拿到的数据是浏览器,因为我这个例子是WEB应用,所以他能拿到的是浏览器信息,像负载均衡、CDN、前端入口等等。像我们WEB服务器可以拿到的日志就是网站的访问日志。数据库,中间件或者是缓存RDS,能拿到的数据是什么呢,一个是核心服务的日志或者是监控数据。像RDS就是能拿到具体的监控数据,中间件是本身自己可能,看这个是使用什么样的中间件,常规的中间件它自己会有一部分日志会流转出来,或者也可以定向去采集它都可以的。
最后一部分,我们能在服务器底层能拿到什么样的数据呢?也就是服务器的运营日志,可能是操作系统级的运营日志。还能拿到我们服务器的监控数据,服务器可以通过给它装一个监控工具,客户端,然后可以把这些属于搜集上报到工具中去。
这是非常常见的WEB应用的工作流,那么这个工作流背后我们要去思考的是,具体能拿到什么数据呢?以案例来看,能够拿到服务器访问日志、CDN的日志、数据库的数据等,这一块是我们放在阿里云的SLS也就是日志服务里面的应用日志,也就是我们在开发过程中我们特别埋了一些点,取了一些日志,这个日志我们存在了阿里云的SLS里面。
在大数据方面,我个人有一个感触,大数据转型一定要有懂业务的人来推动,由技术人员推动的大数据转型往往都不落地。这并不是否定技术人员的能力,而是说一个纯粹的技术人员来推动的大数据,往往找不到合适的场景,就会把整个业务或者是公司的转型方向带偏了,可能追求的东西很有技术价值但是不一定有商业价值,这是一个很大的忌讳,这是我这几年的最大感触。很多公司喊着要做大数据转型,但是最后主导都是说找一个什么大数据工程师或者是架构师帮你做方案,最后落地完了之后做跟没做没两样,这也不是我们想达到的效果。
我举一个很有代表性的板块给大家来看一下,就是我们的客户端信息能够搜集到哪些呢?比如说像我们浏览器品牌,像你用的是火狐,Google还是IE还是别的什么品牌的浏览器,你是在请求的时候是可以看出来的,因为现在浏览器都在构造请求头的时候都会把自己的品牌加进去,这个是一定会有的一个东西,除非黑客,黑客通过TCP直接构建请求的,他可以把这些信息抹掉或者是刻意伪造一下,这个主要是用来像爬虫采集,可能会出现这种情况,但是也都有一定的能识别出来的,稍微有一点点经验的人都可以看到,哪一些请求是采集,哪一些是正常访问。然后客户端另一个情况是,早期服务器的访问日志来看,能够看到的信息其实不多,但是近几年来发现看到的信息越来越多了,能看到我们的系统版本IOS是几点零或者是window的什么版本或者安卓什么版本,现在还可以看到我们客户端是用什么设备请求的,这个可能是它直接通过IOS或者是安卓这样一个平台来告诉你,我是什么样类型的一个设备,也有可能他把设备类型直接写在请求头里面了。
有一些请求是我们客户端故意附加给我们的,这个没有什么实际用途,只是说我们在做开发的时候故意这样去做的,最常见的是什么呢?最常见的是我们去看微信的请求,通过微信请求访问你自己的页面会给你附加一大堆的其他信息,这些信息可能并不是说对你完全有用的,但是会传给你,具体怎么使用是你自己分辨的一个问题。或者说我们自己APP里面内嵌的混合开发的H5页面,那这些页面也可以通过由APP客户端去注入一些信息到请求头里面去,这样也可以把这些信息发到服务端,也可以在服务端进行搜集,这是客户端上面能拿到的信息。
访问信息能拿到数据有几个呢?一块是来源IP,这个是最最重要,你一个请求主要是基于互联网请求,你过来一定会有来源IP,这个跑不掉的,无论你是通过代理还是不通过代理,你总归会有一个来路,这个来源IP会帮我们分析很多问题,安全领域也好,大数据分析领域也好,它都很重要。第二个是我们的请求地址,就说这个IP发起的一个请求,请求的是什么样的一个UIL,请求的是什么样的页面或者是接口都在访问信息里面可以看到,还有一个请求时间,这个是也是挺重要的,服务器会记录这个请求是什么时候发过来的,这主要是为了帮助我们做分析的时候把这个请求套路到时间点里面去。
我们还能拿到用户信息,我们怎么去拿这个用户信息把它记录下来呢?一般来说就是说我们在几个点,一个我们浏览器里面可能会有一标志符等可以记录用户的UID信息或者是反查出来UID信息,或者是通过业务应用在工作过程中埋点,去产生这些东西。有了UID之后我们还可以搜集到更多的,其实这个用户所有的信息其实都能拿到的像昵称,性别等等更多信息。那么业务信息往往就是我们某一个请求发过来之后,具体对应的是什么业务的语言数据是可以通过业务信息这一块分析出来的。比如说我一个安卓的手机,使用了Google的浏览器访问了我的页面,然后这里来源IP是多少多少,然后请求的地址是什么。请求的地址里面我们可以去拆分一下,在这里面找出我们的新闻标识。这是一种方式通过UIL去分析,这个就比较硬核一点,你需要对你的业务有非常多的了解,如果你的业务系统是由不同时间开发的,又是不同人开发的,然后业务系统又很复杂和庞大,这种方式可能就不太适用,因为你适配每一个请求地址的时候,你要写的增值表达式或者是清洗的过程会很长。
还有一种就是我刚刚说的在应用工作过程中埋了点,把这个日志打出来了,这个是最简单的,有了这个表示之后我们可以找到标题分类,这只是举例子,如果你是一个电商可能通商品表示可以找到商品名、商品分类、商品描述等等,这也是我们业务信息的梳理。
数据开发的第一步
很多人说我大数据要去做开发,要去入门,然后我从哪一步开始,其实我告诉大家,最简单就是你先从梳理数据结构开始。你要有看数据结构的能力,你要很强的逻辑性和业务敏锐度,去把这些信息整合到一起。比如说我们的客户单信息、访问信息、用户信息、业务信息这四块都拉成了一张二维表,比如浏览器、设备、昵称、性别,通过UIL的分析可以直达新闻的ID是多少,通过新闻ID可以找到标题,分类,内容等等这些信息。
这就是我们现在要做的第一步,先把这个表整出来,这是最重要的。因为你有了这张表之后,你才能去定向各个数据源去抽数据,然后去拼成这张表,如果你连这张表都没有,你根本不知道自己下一步怎么去执行,这是大数据要落地,技术要去落地的第一步就是数据的搜集。
四块基础数据我们合并拼接成了一块二维表,就是有点类似于电子表格或者是关系数据库里面的一张表。但是这个是很初级的一个过程,你即便把它拼出来也不代表有什么用,比较浅。它背后还有东西,是什么?
第一个我们来看访问信息,访问信息里面有来源IP,有请求时间和请求地址。请求地址通过简单的清洗,就把它分析出来它请求你是什么ID或者是什么业务系统等等信息。请求IP其实是可以做很多很多事情。比如说一个IP你可以通过反查知道,这个IP是属于什么通讯服务商,电信移动联通还是什么别的国家什么服务商,那么你还可以通过一个IP知道这个人大概的区属位置,比如说他是中国的还是美国的,当然中国的IP是很全的,就是有商业版有非商业版,开源的一些IP地址库,反正准确率都还行,如果说你有一些很严格的用途,你可以去找商业的版本去用。它可以通过IP地址第一能获取到这个IP对应的是什么通讯服务商,比如说我今天给大家直播用的是中国电信的宽带,那么中国电信的宽带去访问阿里云的官方网站,那么阿里云的官方网站生成一条日志看到我这个IP去查一下就知道,这个用户的请求是从中国电信IP那儿过来的,能知道他的通信服务商。知道通信服务商之后,我们还能知道这个人的国家,因为IP地址是每个国家是有每个国家同的IP地址的区划,这个大家学网络课的时候都知道。那么基于这个国家之下,可能每个国家内部针对各个IP段还有一些分配,这是一种。
第二种可能就是像BAT去做了一些IP地址的跟踪识别。通过域名去把公网IP输入进去能告诉你什么国家,是什么通信服务商。然后省市区县这一块可能就需要商业级别的数据库来支持你。但是我们目前来看这个好像是开源免费的数据库,你查出来也挺准的,至少省市是准的,但是区县不一定是准的,但是前两个一定是准的。
由此可见,从来源IP这个简单的字段我们能分析内容就很多了。那么我们通过用户信息和业务信息又能分解出来什么东西呢?
左边相当于是生成自清洗带来一个数据,就是你的额外数据。右边这张表用户信息和业务信息这两张表,一个是用户标识也就是我们常说的UID,一个是我们新闻标识,也就是我们信息ID。这两块ID能够拼合成什么样的数据或者能帮助我们带来什么新的东西呢?
举个例子,我可以通过关联下钻的方式去找到这个用户以及这个ID关联的信息。比如说这个用户看在这篇新闻的同时,他发了评论,那你就能把他评论数据找出来,发了评论之后,他可能还收藏了这篇文章或者是点赞了这篇文章,也可以把收藏和点赞的数据关联出来。这样过程,前者可以通过一些辅助手段去解析我们字段把他拆解出一些更有用的信息,后者是通过我们业务逻辑去通过数据下钻去找到深层次关联,这是我们数据背后就是两种处理的方式,就是解析处理的两种方式。目的是什么?目的是为了把我们的数据拆分的更细致,然后更全面,因为我们以前做大数据跟我们业务系统开发是完全不同的两个概念。也就是说我们以前做开发的时候,涉及到数据库,可能更多是为了让查询起来更快,或者让它能够不要爆发式增长,占用我磁盘IO,不要写入太多的数据,尽量能够精简,能够通过一些别的方式关联出来,就行了,也不要求说在我的数据库里面要知道这个用户,能实时知道在某一篇文章下的评论,这个可能是我们业务需要,不是我们的架构需要,所以我们在做架构的时候就把这一块弱化掉了。因为我们做大数据的时候,我们要逆向思维,要把我们原来技术架构精简掉的东西全部都找出来,然后推翻掉,然后重新给装满。所以我们通过这几幅图和背后的关联关系,可以引申出来一个我们现在要说的,我刚刚通过这种方式为我的这张大表增添了几个新的链,比如说像通信商和地址,就是通过IP地质可以查到通信商和国家的。
因为PPT的行数限制,所以我画了一个无穷大的符号在那里,就是说可以通过这些数据延伸出来找到更多的信息和数据,它全部可以排在后面。那么有的同学可能会比较好奇,你干嘛一定要把一个数据全部联想成一个扁平的东西。那是因为我们在实际操作过程中,大数据并不意味着一切都要不关联,然后全部都放再一个大表里面,这也不太现实。但是大数据讲求的最重要的一个点是,你在某一个维度上你要尽量去全面和平衡,不要太去计较我们什么空间的占用,写入的速度或者是会不会影响到什么索引,你所有的这些数据库的思维都可以抛弃掉。因为大数据分析之间事情本身不像业务系统,有那么高的实时性的要求或者说有那么高的业务可靠性上的要求。
我们通过对数据的拆分,多表打平成一张表。我们前面可能时间浏览器和设备这些都来源于日志,然后这一部分都是来源于日志,这两个来源于清洗,昵称、性别、新闻ID、标题分类这些来源于数据库,这些来源于关联查询出来的一些数据等等。就这张表数据来源可以很多,但是最终一定要有一个结构化的东西去把它存下来,当然也有不结构化的数据,但是因为我们今天说做大数据,不是说你已经是一个很成熟的公司在做这个事情,是我们很多公司是要转型做这个事情,那你第一步只能从这个方式去开始。
这是我的一个感受,大数据第一步就是把破镜圆回去,人家说破镜重圆,因为镜子裂了就没有办法再圆回去了,但是我们要做大数据规划和架构的时候要有逆向思维,这个逆向思维,逆的是什么,逆的是我们传统业务架构。我们要沿着这个镜子原有痕迹把它拼回去,你不能说逆着逆着数据风马牛不相及了,那也没什么价值。所以我们要通过把割裂的数据关联起来,数据是割裂的,但并不是没有逻辑的。
很多人说我要去做大数据转型了,第一步我先选一个平台,云平台还是开源平台,然后再选一堆工具链,选完工具链之后我一百万找几个大数据工程师,然后再如何如何。我见过太多的公司是这样做,但做不成功。我觉得这是大家需要去规避的一个坑。大数据不是说你先去选一个平台,一个工具,再招一堆人再来思考怎么去做,一定是先从业务出发,把我们已有的这些东西全部思考清楚了,你再去找一个懂业务的人去推动它,带着技术人员一起去做大数据转型,这是我大数据从业这么多年的感受,分享给大家。
作者:阿里云MVP戚俊

时间:2019-02-25 23:01 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关推荐:
网友评论:















