大数据的过去、现在和未来:解读《大数据四十二条》
作者:傅一平 来源:与数据同行
它山之石可以攻玉,何宝宏博士就是一个吧。
何所思(ID:gh_9820d1a2e9ef)是一个非常有特点的公众号,它的主人叫何宝宏,这个公众号这样介绍自己:一个从事互联网研究 20 余年的老兵,对技术和产业的思考。
然后网上搜索了下:中国信息通信研究院云计算与大数据研究所所长。最近他还出了本书:《风向》。
自己不认识何宝宏,偶然看到他的这篇《大数据四十二条》文章,觉得有趣有料,本来想转载的,可惜找不到联系方式。
由于没有转载权限,我只得在这篇文章的基础上扩展出我的理解,直到绕过腾讯原创的检测,没想到一扩展就成为了万字长文。
《大数据四十二条》是何博士关于大数据本质的一些总结和思考,每一条都是简单的一句话,共 42 句,但每一句似乎都意味无穷。
这让我想起中国古代哲学的一个特点,就是“言有尽而意不穷“。语言的作用不在于它的固定含义,而在于它的暗示,引发人去领悟道。
现在我这个登徒子就要去破这个道了,在尝试解释的过程中,笔者发现自己对于大数据的过去,现在和未来竟然多了些体会,下面我们就开始吧。
第一条:每个时代的人,都会认为自己所面对的数据太大了
第二条:每个时代对大的理解都不同,古汉语中“三”就很大了,后来是“九”
这两条其实要表现类似的思想,笔者就一起解释了。
从人类诞生以来, 人类社会至少已经经历了四次意义重大的信息传播革命,每次革命的起因都是因为信息量的海量增长导致需要用新的技术去处理它,每一次信息传播革命都把人类文明推向一个新的发展阶段。
第一次信息传播革命是语言传播的诞生:提高了人类信息传播的质量、速度与效率。
第二次信息传播革命是文字传播的诞生:使得人类的信息传播革命第一次突破时间、空间的限制, 得以广泛流传和长期保存。
第三次信息传播革命是印刷传播的诞生. 报纸、杂志、书籍等印刷品大众媒介迅速普及. 第四次信息传播革命是模拟式电子传播的诞生
特别是 20 世纪以来,伴随着信息化、互联网、移动互联、物联网的发展,生成数据的基础设施、采集数据的基础设施,连接数据的基础设施大幅增加,产生了超过以往历史总和的海量的数据,为了更好的从数据中获得知识,这个时代发明了各种大数据技术 + 人工智能算法来处理这么庞大的数据。
从笔者个人的经历也可以很明显看出来,读中学的时候觉得几 K 就很大,读大学的时候觉得几 M 的软盘很大,大学毕业了觉得上 G 的光盘好大,工作几年觉得几百 G 的数据仓库好大,工作 10 年几十 T 的数据觉得传统的数据仓库已经撑不住了,现在面对的是几十上百 P 的数据,你突然发现还是太大了。
第三条:所谓大数据,就是一个如何将数据变小的过程
大数据的一个特点就是价值密度低,需要从海量的大数据中获取你需要的东西,就是一个从数据到信息到知识再到智慧的让数据不断变小的过程,比如数据仓库的分层设计就是这样,数据越偏向应用,最后留存的数据就越小,基于越小的数据才能归因业务做决策。
我们从海量的 1T 的数据中挖掘到的知识最后往往只要用 1bit 就可以表示,即 1 或者 0。
第四条:2019 年,大数据的“大”已不再是核心问题,核心是如何更快,比如流计算
大数据的四个特点中,处理速度快正在成为核心,为什么?
一个当然是人工智能时代深度学习等算法需要更强的算力,传统的技术架构已经很难满足,另一个是数据在时效性上的价值越来越大,笔者在很多文章中都提到了实时数据中台的建设,流处理已经不仅仅是个独立应用的问题,而是海量的实时应用如何快速开发部署的问题,当然这个快还包括了分析查询的快,即时计算的快等等,这些都需要诸如麒麟、易鲸节等引擎的支持等等。
信通院在 2019 年的《大数据白皮书》中提到大数据技术的一个关键词是融合,融合的目的就是适应各种场景的快,包括:
(1)算力融合:多样性算力提升整体效率,如 GPU、FPGA、ASIC 等等
(2)流批融合:平衡计算性价比的最优解,如 Flink
(3)TA 融合:混合事务 / 分析支撑即时决策,如 OLAP 与 OLTP 的整合
(4)模块融合:一站式数据能力复用平台,阿里叫作大数据产品全链路化,比如浙江移动的 DM 平台,贯通了从数据采集到应用的全过程
(5)云数融合:云化趋势降低技术使用门槛,大数据基础设施云上迁移势不可挡,如我们的 PaaS 都是云上集成,业界比如阿里的数加等等
(6)数智融合:数据与智能多方位深度整合,如我们的敏捷挖掘平台,不再需要在数据和 AI 两种平台之间搬数据
第五条:数据大了价值不一定就高,价值更可能被大噪音淹没掉
其实反过来说也一样,而且更具韵味,数据量越大,数据的价值密度不一定就越低,两者之间并没有必然的关系,这个结论有以下的一些解释:
(1)从采集的角度来看,传统数据基本都是结构化数据,每个字段都是有用的,价值密度非常高。大数据时代,由于存储的价格越来越低,越来越多的半结构化和非结构化数据都可以随便存储,这些数据在采集的时候很多时候都没想清楚有什么用,相对来说就成了干扰价值数据的噪声。比如网站访问日志,里面大量内容都是没价值的,虽然数据量比以前大了 N 倍
(2)从挖掘的角度来看,从更多的数据中挖掘出规律,显然面临着更大噪声的挑战,因为数据越多可能形成的模式就越多,意味着训练的时候寻找匹配模型的代价就越高,因为噪声增加了。
第六条:主张让大数据放弃追求因果关系,就是要让我们回退到巫术时代
这句话我是认同的,《大数据时代》这本书提到要追求相关关系,其实是大数据以用为上的特定阶段的功利性表现。
从短期来讲,由于技术上的便利性使得追求相关关系可以获得当前较高的经济性价比,但从长期来讲,理解因果关系始终是提升效率的最高办法,因果关系是本质,相关关系是表象,理解了因果你就可以有更正确的做事逻辑,可以进行大量的迁移学习,而相关关系只能在一种特定的场景中使用。
万有引力定律也是模型,首先是有相关关系,然后还挖掘出了更深层次的因果关系,否则牛顿也许只能将这个相关关系应用在苹果落地的场景,而根本不可能衍生到万事万物。
只能理解相关关系一定程度是业务能力不够的表现,比如业务的解释,理解了啤酒与尿布的业务本质可以让我们移情换位,起码你能推测出英国男人也许还需要顺带购买些奶粉。
商业领域,科技领域,科学领域与哲学领域对于大数据的要求是不一样的,比如追求因果是科学领域始终的梦想和要求,从来不会改变。
第七条:主张大数据不再采样而是全集,只是技术外行的 YY 而已
一方面受限于我们的能力,我们采集的任何数据都是有限的,而且数据能否采集全到最后其实是个哲学问题,比如首先要解决这个世界到底是连续的还是离散的问题,其次要解决我们能否具备完备的采集条件问题,最后还要解决采集设备的能力问题,因此当前其实所有的采集都是采样,只是程度不同而已,我们只能说利用新的传感器采集的数据维度多了,粒度细了,而不能说是全集。
第二方面是大数据机器学习的基础是统计学、概率论,你还是在基于采样的基础理论来进行实际的数据分析工作。
第八条:大数据主张用数据说话,但数据也会说谎,而人类更喜欢听故事
面对同样的数据分析,可以给出不同的结论,关键点除了数据,还在于做数据分析的这个人和使用数据的那个人,学霸和学渣的区别大多时候可不在于看得东西不一样,而主要在于思考的能力,在社会上,当然还包括道德水平。
关于人类更喜欢听故事是因为基因的设定,理性的一本正经的阐述和声情并茂的具有画面感的阐述显然后者更容易吸引人,即使逻辑不堪一击。因此我们要努力跟基因的设定进行多抗。
有大量的书在阐述这个道理,比如《统计数据会说谎》,可惜我们还是会不自觉的陷入这种困境。笔者就不太信任这类媒体,时常用不标注数据来源和统计方法的方式来给出一个哗众取宠的结论。
第九条:数据的内涵在不断丰富中:数据是信息,数据是资产,数据是隐私,数据是可回收垃圾 (如大数据),数据是有害垃圾 (如 DDOS 攻击、垃圾邮件) 等
数据是信息是因为数据管理体系会为裸奔的数据赋予业务含义,数据是资产是因为当前数据已经具备了资产的三个特征或接近这三个特征:企业拥有和控制;能够用货币来衡量;能为企业带来经济利益。
当然企业拥有和控制还面临数据确权的问题,用货币对这些数据进行衡量也是个复杂的问题,但基本上,数据列入企业的资产负债表可能只是时间问题。
数据是可回收的垃圾是因为用过的数据还是能迅速回来继续创造价值,其回收的速度相对于一般的实体真是快太多了,数据是有害垃圾是因为人的原因,跟数据本身没有关系。
第十条:数据的内涵日益丰富,将导致管理技术必然走向碎片化、层级化或分布式
这里仅仅从技术的角度去理解内涵。
数据技术的碎片化是因为数据的使用场景太丰富了,为了满足特定场景需要采用不同的数据技术引擎,无论是离线的还是流处理的,是在线计算还是在线查询的等等。
数据技术的层级化是为了满足不同层次的业务需要,比如数据仓库的基础层标准化是为了书同文车同轨,保留最大的细节和支撑的可能性,融合模型层是为了灵活快速的满足前端应用的需要,应用模型层是为了直接满足应用的需要。
数据技术栈的日益复杂和增多使得层级化的管理方式越加必要,比如数据采集、数据存储、数据处理、数据服务、数据查询、数据应用等等,合理层级划分的目的是为了管理简单,提升最终效率,比如是否要拆分出服务,数据存储和数据处理是否要合并等等。
现在如火如何的数据中台就是希望用层级化的切分方式最高效率的为前端赋能,现在到处可以听到“前店后厂”,“大中台,小前台”,“前台,中台,后台”的概念,都是层级化思维的体现。
数据技术的分布式是主流了,现在没有分布式能力的技术引擎越来越难看到了。
第十一条:数据管理技术正在:1)底层数据模型,2)业务方向,3)架构方式和 4)处理时效性,从四个维度四散开来
底层数据模型强调数据标准,构建一套完整的数据标准体系是开展数据标准管理工作的良好基础,有利于打通数据底层的互通性,提升数据的可用性,近期笔者参与的《数据标准管理实践白皮书 》就力图做些指导。
业务方向很容易理解,现在大数据早从 Garner 曲线消失了,说明其已经从一个时髦的技术概念演进到了应用阶段,你公司建设完大数据平台的第一天,就要考虑大数据创造价值的问题,这可比建一个大数据平台难多了。
架构和处理时效性前面已经说了,这里不再累述。
第十二条:分布式的浪潮最早发生在分析型和非关系型领域 (即传统大数据),现在杀了个回马枪,回到事务型和关系型了
传统的业务应用在做技术选型时,会根据使用场景的不同选择对应的数据库技术,当应用需要对高并发的用户操作做快速响应时,一般会选择面向事务的 OLTP 数据库;当应用需要对大量数据进行多维分析时,一般会选择面向分析的 OLAP 数据库。
随着数据越来越大,传统的数据仓库已经难以有效应对数据处理和分析的挑战,以 hadoop(NoSQL)为代表的分布式计算框架应运而生,它们能有效解决海量的离线分析的需求,这就是所谓的传统大数据的分布式浪潮。
但在数据驱动精细化运营的今天,海量实时的数据分析需求已经提升日程,无论是实时营销或是实时风控,都需要 OLTP 系统具备对于海量数据的实时分析能力,即事务和分析一体化,离线的分布式大数据框架在时效性上已经难以达到生产的要求。
混合事务 / 分析处理(HTAP)是 Gartner 提出的一个架构,它的设计理念是为了打破事务和分析之间的那堵“墙”,实现在单一的数据源上不加区分的处理事务和分析任务。
这种融合的架构具有明显的优势,可以避免频繁的数据搬运操作给系统带来的额外负担,减少数据重复存储带来的成本,从而及时高效地对最新业务操作产生的数据进行分析,比如行列数据库的优化等等。
不知道我的解释是否切题?
第十三条:数据分析技术的几个发展趋势:向上与 AI 融合,向下与云和异构计算结合,中间正流批结合、分析事务融合和一体化等
从分析方法的角度看,大致有三个层次:统计分析(对比 / 分组 / 趋势 / 结构)、数据分析(相关 / 方差 / 验证 / 回归 / 时序)、数据挖掘(分类 / 聚类 / 关联 / 异常),可以预见,未来的数据分析对于算法的依赖会越来越高,在数据挖掘中大量的引入 AI 是显然的。
从处理能力的角度看,云化趋势降低数据使用门槛、多场景要求多样的分析引擎、OLAP 与 OLTP 紧密融合满足在生产流程中实时的业务分析要求也是大势所趋,这个在前面也已经提到过。
第十四条:大数据是因为数据大,区块链是因为数据贵
“大”是大数据的一个明显特征,当然大也是相对的。区块链为了解决数据可信分布式账本问题,本质上就是个缓慢、昂贵的数据库,你去看看区块链处理数据的成本就能理解为什么区块链上的数据这么贵:
(1)开发更严格、更缓慢:创建一个可证明一致性的系统并非易事,所有这类系统一开始设计时就确保一致性。区块链中没有“快速行动,打破陈规”(move fast and break things)一说。如果你打破了陈规,就丧失了一致性,区块链就会损坏,毫无价值。你可能会想,为什么就不能修正数据库或重新开始、继续前进?这在集中式系统中很容易实现,但在去中心化系统中很难实现。你需要共识,即系统中所有参与者达成一致,那样才能更改数据库。
(2)奖励结构很难设计:增设正确的激励结构,并确保系统中的所有参与者无法滥用或破坏数据库,这同样是需要考虑的一个重大因素,为了一次记几个 BIT 数据的账,你去看看我们为了挖矿耗用了多少计算资源就知道了。
(3)维护成本非常高:传统的集中式数据库只需要写入一次,区块链需要写入数千次。传统的集中式数据库只需要核查一次数据,区块链需要核查数千次数据。传统的集中式数据库只需要传输一次数据以便存储,区块链需要传输数千次数据。
(4)扩展起来确实很难:扩展起来其难度比传统的集中式系统至少高出几个数量级。原因很明显。同样的数据要放在成百上千个地方,而不是放在一个地方。传输、验证和存储的开销很大,因为数据库的每个副本都要承担这笔开销,而不是在传统的集中式数据库中只要支付一次那些成本。
比特币这个应用能流行是因为不需要太多升级改变,传输的数据又很少,区块链中如果你要让海量的数据上链,基本上属于天方夜谭。
第十五条:数据可视化是因为机器看懂了但人看不懂,AI 是因为人看懂了机器看不懂
机器对数据是很敏感的,而人对数字天生不敏感,需要用画面感来刺激大脑关注,因此何博说了这是做数据可视化的原因。
而人工智能反过来,比如人对于猫能快速的识别而机器就不行,它需要训练。当然这里就存在不公平性,其实人出生的时候也不认识猫,只是训练后了才认识的,而且人出生的时候基因天然就带了粗糙的认知框架,比如婴儿看到蛇天生就会还害怕,这显然不是后天训练出来的。
但考虑到认知,意识等能力到现在为止人工智能还搞不定,因此这句话还是没错。
第十六条:开源已经垄断了大数据生态
我们原来没多少原创是公认的事实,其实也蛮好,师夷长技以制夷嘛,当然这句话放到现在的确有点绝对化,换个词:开源和闭源并驾齐驱。
第十七条:云计算的优点主要被城里的数据享受了,环境破坏的代价却留给了村里的数据,于是就有了边缘计算
云计算对于带宽,时延有非常高的要求,距离云比较近的数据可以享受着云计算带来的各种便利,但处在远方的数据由于昂贵的带宽和时延导致无法有效享受这个红利,因此它们考虑就近利用一些本地的设备来做些数据的加工(显然这对本地的设备要做大量的改造),然后将加工后的极小的数据传送到云端去做处理,这样带宽和时延就都能满足,所谓边缘计算。
第十八条:大数据被夹在两座大山中,一边是隐私要保护,一边是资产要流通
第十九条:一年来,GDPR 带来了全球隐私保护立法的热潮
第二十条:你不能在拥有 100% 安全的情况下,同时拥有 100% 的隐私和 100% 便利性
这三句话都很好理解,隐私和变现是双刃剑,但谁能走好这根钢丝?立法的平衡点在哪里?
第二十一条:现在,每个人的数字化身都是数字奴隶,没有归宿的灵魂在数字世界里飘荡
第二十二条:现在电话号码是隐私,而 30 年前,会公开刊登在邮局的黄页上
第二十三条:你没有隐私, 忘记这事吧
第二十四条:1993 年,”在互联网上,没有人知道你是一条狗”。而在大数据时代,没有人不知道你是一条狗
第二十五条:现在,人与人见面打招呼“你还记得我啊”,是一种幸福。将来,打招呼时说“我还记得你啊”,是一种威胁
这五句话也在讲隐私,只是从多个角度去看隐私的变迁,考虑到你的私人数据都是记录在别人的电脑里,你竟然在法律上还无法确认这个权利,只能任由你的数字孪生被别人开采蹂躏,而且还可以通过这个数字孪生对你这个本体产生影响,似乎有点匪夷所思。
而过去由于号码清单的商业价值不大,比如量很小,打电话又很昂贵,获得的收益肯定还没电话费多,因此即使是隐私也没人会用,都是利益驱动造的孽。
第二十六条:数据资产化,资产数据化,数据托管化 (云)
数据帮企业赚取利润的过程就是数据逐步资产化过程,资产数据化大概就是指数字化货币吧,比如比特币,资产你不需要实体,只要拥有一个靠得住的大家都认可的一个数据就可以了,数据托管化就是你自己的数据以后不用存在自己电脑上,也不需要买,统统上云让别人帮你保管,啥服务都有,而且比你自己买的成本还低。
第二十七条:2019 年,业界从关注数据技术,转向了关注数据资产
大数据技术早就从 Garner 消失了,现在大家都希望找到大数据应用的场景,直接创造经济效益,加速数据资产化的过程,现在说得最多的就是数字化转型和产业互联网。
第二十八条:以前数据更多的是信息,现在数据更多的是资产
信息是数据经过加工处理后得到的另一种形式的数据,这种数据在某种程度上影响接收者的行为,具有客观性、主观性和有用性,信息是数据的含义,数据是信息的载体,现在数据转化为信息已经不够了,懂含义可能没啥用,大家能希望将数据转化成知识或智慧从而产生经济价值。
第二十九条:传统的三大数据管理框架,都假设数据是信息,而不是资产
三大管理框架是 dama、cmmi-dmm、dcmm,不知道对不对?
第三十条:就像河伯还没遇见大海时,任何企业所拥有的大数据其实都是小数据
企业必然是属于某个行业,而这个行业的经营业务范围决定了其拥有的数据边界,阿里帝国无论如何膨胀,最多把数据粒度做的更细,而无法做到无限宽。
第三十一条:数据流通,还处于男耕女织的时代
第三十四条:亟需数据流通的经济理论突破,这个问题是诺奖层级的,当然也可能是图灵奖的
在数据的归属问题未解决前,在数据的标准化未建立之前,在数据的价值未有效衡量之前,在数据的壁垒未有效打破之前,在数据的道德规范未建立之前,围绕这些问题相关的法律法规未制定之前,数据流动只能采用小作坊的探索方式,风险也是很高的,谁能解决这个问题当然是牛逼的很。
第三十二条:比特是计量数据规模的基本单位,不应作为计量数据流通价值的基本单位
笔者写过一篇文章《数据的价值到底如何评估》来衡量数据价值,即用供需来判断这个数据的价值,当然还有很多方法,包括周期、频度、成本等等,但数据的可复制性决定了不可能按量计费。
第三十三条:经济学是建立在工业经济的假设上的,而现在已经是数字经济了
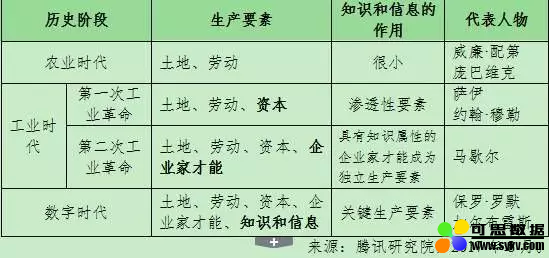
生产要素是人们从事商品和劳务生产所必备的基本资源,是一个历史范畴。英国著名经济学家威廉·配第曾指出:“土地为财富之母,而劳动则为财富之父和能动的要素。”这恰如其分的阐明了农业时代的生产要素——土地和劳动。
18 世纪 60 年代,以“机械化”为基本特征的第一次工业革命爆发,人类社会进入工业时代,机器设备这一物质资本成为决定经济社会发展的第一生产要素。
19 世纪下半叶,以“电气化”为基本特征的第二次工业革命爆发。随着社会化大生产的发展,资本的作用进一步强化。同时,资本所有权与经营权日益分离,企业家从劳动大军中脱颖而出,成为一个新的群体。企业家才能开始成为独立的生产要素。
上世纪 80 年代开始,信息通信技术蓬勃发展,数字革命开始兴起。特别是当前以云计算、移动物联网、人工智能为代表的新一轮科技革命席卷全球,信息技术与经济社会以前所未有的广度和深度交汇融合,人类社会正在被网络化连接、数据化描绘、融合化发展。
知识和信息的充分挖掘和有效利用,推动了诸多领域重大而深刻的变革,极大改变了人们的生产、生活和消费模式,对经济发展、社会生活和国家治理产生着越来越重要的作用。数字化的知识和信息作为关键生产要素,推动人类社会进入全新的数字经济时代。下表显示了生产要素的变迁规程:
第三十五条:信息技术革命前人类是信息的饿汉,就像工业革命前人类是食品的饿汉
这个很好理解。
第三十六条:拥有知识的不一定是知识分子,也可能只是个知识的吃货
引用何博的自己以前文章的解释:
其实就是在讲信息革命前由于传播困难,很多知识分子利用信息不对称占尽优势,但信息革命后,吃再多知识的胖子,也没有互联网知道的多,因为知识富足后人类需要的是智慧,大脑的 CPU 快烧掉了,神经网络快堵住了,内存快失效了,消化不了这么多知识了,出现了信息焦虑,连接恐惧。
遍地都是知识的吃货,知识的胖子,却越来越缺乏独立思考和智慧。为给知识胖子减肥,减少垃圾知识的摄入,需要提高知识的消化能力,是当务之急。
第三十七条:数据是 21 世纪的石油,但别忘了 20 世纪前石油不是战略资源
第三十八条:石油应用也曾经历过至暗时期:当洛克菲勒让石油 (煤油) 主要用于照明时,爱迪生发明了电灯。石油的主要用途转向动力,是因为汽车的发明和亨利福特将其平民化
这两句话隐含的含义是数据如果没有应用的极大普及,就没有战略价值,正如动力应用让石油成为了战略资源一样,但现在广告和金融已经让数据先飞起来了。
第三十九条:记忆是例外,忘记是常态,于是我们发明了文字、书籍和大数据来当人脑的外设。人类社会的诸多规则和习惯,是建立在人人都有健忘症的假设上的,但这个假设正在被大数据连根拔掉
有了数字孪生,你所有的信息都被自动记录,因此未来靠记忆获取的任何优势都将灰飞烟灭,比如让孩子练习心算纯粹是浪费时间,以前的这些规则和习惯也许逐步会成为一种艺术展示,陶冶情操而已,现在你提笔忘字有很大问题吗?
第四十条:算法是数字世界的运行规则
算法是处理信息的本质,因为程序本质上是一个算法来告诉计算机确切的步骤来执行一个指定的任务,是一系列解决问题的清晰指令。
算法代表着用系统的方法描述解决问题的策略机制。在数字世界中,算法就是权力,是虚拟世界中的法律和制度。
事实上,整个世界的运行规则都是由算法决定的,不同的学者从不同的角度也对算法进行了诠释。
《未来简史》中,提到了生物是算法,并从生物的生存和繁衍两个角度进行论证。
《原则》中,作者认为自己能取得成功的原因并不是自己知道了多少,而是自己在无知的情况下,知道如何做。作者在生活和工作中对遇到的问题进行不断地总结反思,从而形成做事情的一系列步骤,而这些原则推动了作者取得了今天的成功。
人生脚本中,提出人的命运也是有脚本的,形成于童年时期,他有开始、展开、高潮、结束和尾声。我们后期的人生中,会根据人生脚本不断进行重复。
第四十一条:算法没有偏见,只有人才会有
加纳裔科学家 Joy Buolamwini 一次偶然发现,人脸识别软件竟无法识别她的存在,除非带上一张白色面具。有感于此,Joy 发起了 Gender Shades 研究,发现 IBM、微软和旷视 Face++ 三家的人脸识别产品,均存在不同程度的女性和深色人种“歧视”(即女性和深色人种的识别正确率均显著低于男性和浅色人种),最大差距可达 34.3%。
今日头条创始人张一鸣所信奉那句“算法没有价值观“,但今日头条很多算法的结果却引来了争议,笔者的文章《数据分析师的算法推荐是否会陷入“真实的谎言”?》、《谈谈大数据时代的别被算法困在“信息茧房”》也讨论过这个问题。
那么,算大到底有没有偏见?
我的理解是这样:虽然算法并不会生而歧视,工程师也很少刻意将偏见教给算法,但算法的制作过程不可避免掺杂了偏见,比如数据集的构建缺乏代表性,数据特征的选择有偏颇、人工打标带入的主观性等等,在从人到机的迁移中,偏见习得了某种“隐匿性”与“合法性”,并被不断实践和放大。
因此,机器从未独立创造偏见,但只要有人的参与,偏见就不可避免,从结果来看就是这样。
第四十二条:电磁介质的普遍寿命是 5-30 年,1000 年后“它们”如何考古呢?
这个我倒不怎么担心,定期备份更新呗,比如我 5 年换一次机器,硬盘也顺便捣鼓一次,新的硬盘装新老数据,只要你的新硬盘容量足够大。
恭喜你看到这里,我通过解读,你通过阅读,我们都经历了一次大数据的洗礼,希望你能给出自己更深刻的见解。
本文转载自公众号与数据同行(ID:ysjtx_fyp)。
原文链接:https://mp.weixin.qq.com/s/QUOHU5yAvwIIf0KlQCKkdg

时间:2020-01-11 23:12 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
相关推荐:
网友评论:















